ONE SENTENCE SUMMARY:
布隆过滤器是一种高效的概率数据结构,用于快速检查元素是否在集合中,适用于内存有限的场景。
MAIN POINTS:
- 布隆过滤器使用位数组和多个哈希函数来检查元素的存在性。
- 它在网页缓存、垃圾邮件过滤和数据库中有广泛应用。
- 布隆过滤器存在假阳性、无法删除元素和不支持复杂查询的限制。
TAKEAWAYS:
- 布隆过滤器适合内存受限的快速查找场景。
- 选择合适的位数组大小和哈希函数数量可减少假阳性。
- 对于需要精确集合成员资格的应用,应使用其他数据结构。
你是否曾好奇过 Netflix 是如何知道你已经看过哪些节目?或者 Amazon 是如何避免向你展示你已经购买过的商品?
使用传统的数据结构,比如 哈希表 ,来进行这些检查可能会消耗大量的 内存 ,尤其是在有数百万用户和商品的情况下。
因此,许多系统依赖于一种更高效的数据结构—— 布隆过滤器 。
在这篇文章中,我们将学习什么是布隆过滤器,它是如何工作的,如何在代码中实现它,它的实际应用以及局限性。
📣 提升你的产品技能 - PostHog Newsletter(赞助)

Product for Engineers 是 PostHog 的一份新闻通讯,专注于帮助工程师提升产品技能。它提供关于如何打造优秀产品的精选建议,分享 PostHog 的构建经验(包括错误教训),以及对顶级初创公司实践的研究。
🤔 什么是布隆过滤器?
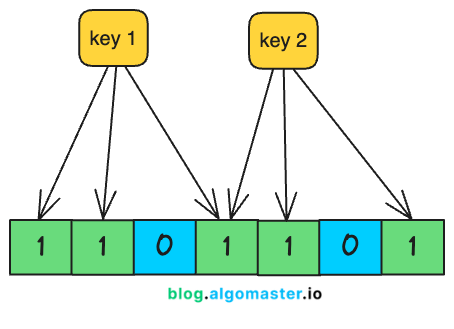
布隆过滤器 是一种 概率数据结构 ,它允许你快速检查一个元素是否可能在一个集合中。
它在需要 快速查找 且不希望使用大量内存的场景中非常有用,但你需要接受偶尔的 误报 。
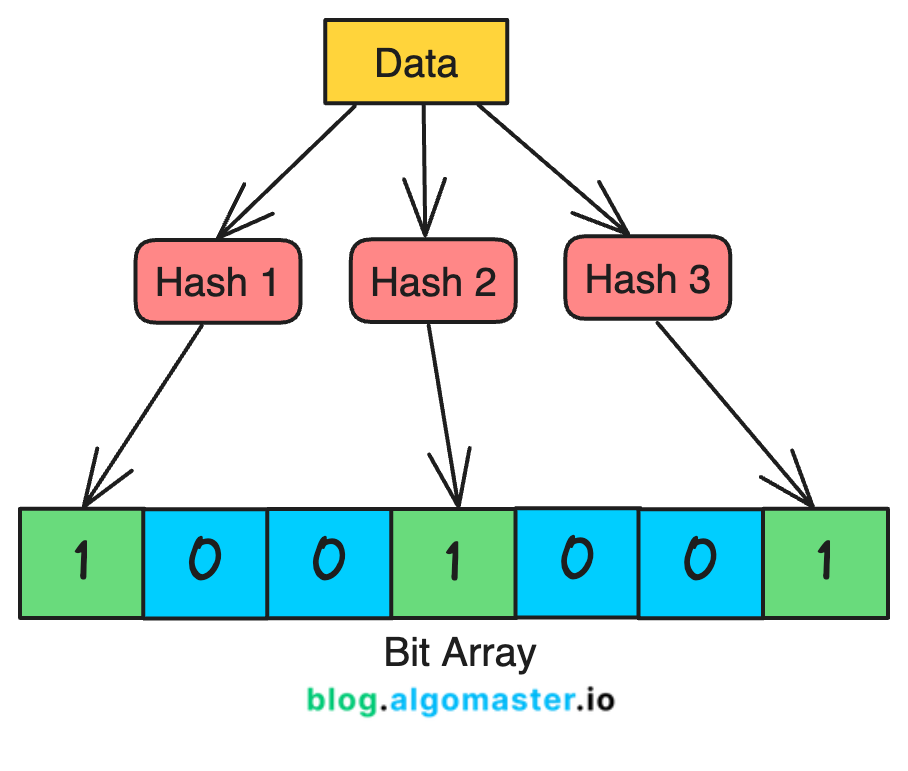
🧩 布隆过滤器的关键组成部分:
-
位数组 :布隆过滤器由一个固定大小的位数组组成,初始时所有位都为零。这个数组用于表示某些元素是否在集合中。
-
哈希函数 :为了添加或检查一个元素,布隆过滤器使用多个哈希函数。每个哈希函数将一个元素映射到位数组中的一个索引。
⚙️ 布隆过滤器如何工作?
布隆过滤器通过使用多个哈希函数将集合中的每个元素映射到一个位数组中。
1. 初始化:
-
布隆过滤器从一个大小为
m的空位数组开始(所有位最初都设置为0)。 -
它还需要
k个独立的哈希函数,每个函数将一个元素映射到位数组的m个位置之一。
2. 插入元素:
-
要将一个元素插入布隆过滤器,你需要通过每个
k个哈希函数来获得位数组中的k个位置。 -
将这些位置的位设置为1。
3. 检查成员资格:
-
要检查一个元素是否在集合中,你需要再次通过
k个哈希函数来获得k个位置。 -
如果这些位置的所有位都设置为1,则认为该元素在集合中(尽管可能存在误报)。
-
如果这些位置中的任何一个位为0,则该元素肯定不在集合中。
🔎 示例:使用布隆过滤器进行URL检查
假设你正在构建一个网络爬虫,需要跟踪已经访问过的URL。
与其存储每个URL(这将需要大量内存),你决定使用布隆过滤器。
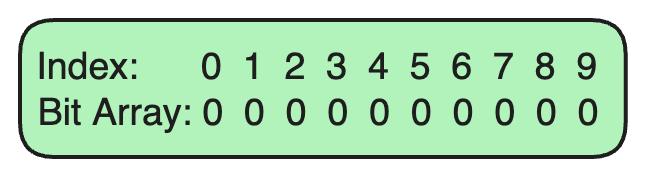
步骤1:设置布隆过滤器
-
初始化位数组 :假设我们的布隆过滤器使用一个大小为 10 的位数组,最初全部设置为0。
-
选择哈希函数 :在这个例子中,我们将使用两个哈希函数。这些哈希函数接受一个输入(如URL)并输出位数组中的一个索引。
步骤2:将URL添加到布隆过滤器
假设我们想将URL
example.com
添加到我们的布隆过滤器中。
-
哈希函数1 为
example.com生成了索引3。 -
哈希函数2 为
example.com生成了索引7。
我们将位数组中索引3和7的位置设置为1。
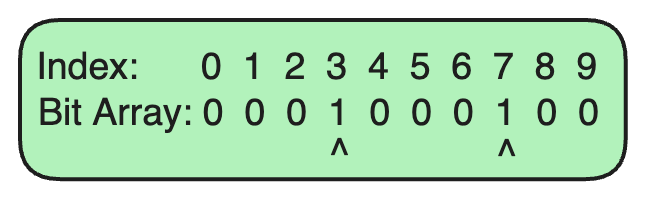
步骤 3:添加另一个 URL
现在,让我们添加另一个 URL,
algomaster.io
。
-
哈希函数 1 为
algomaster.io生成了索引1。 -
哈希函数 2 为
algomaster.io生成了索引4。
我们将位数组中索引 1 和 4 的位设置为 1。
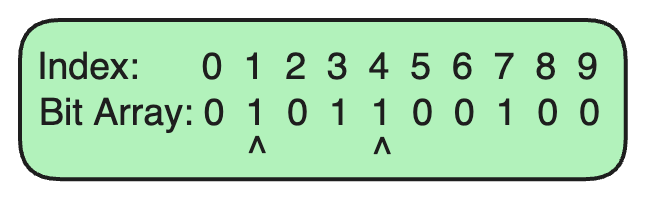
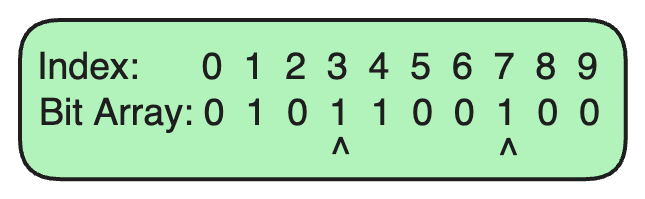
步骤 4:在布隆过滤器中检查 URL
假设我们想检查
example.com
是否已经在布隆过滤器中。
-
哈希函数 1 为
example.com生成了索引3。 -
哈希函数 2 为
example.com生成了索引7。
由于索引 3 和 7 的位都被设置为 1,我们可以说
example.com
可能在集合中
(存在小概率的误报)。
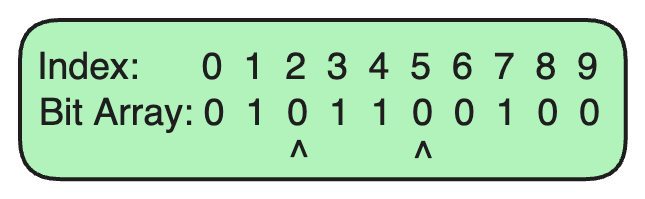
步骤 5:检查一个不存在的 URL
现在,让我们检查一下
nonexistent.com
是否在布隆过滤器中。
-
哈希函数 1 为
nonexistent.com生成了索引2。 -
哈希函数 2 为
nonexistent.com生成了索引5。
由于索引 2 和 5 处的位都是 0,我们可以自信地说
nonexistent.com
不在集合中
。
💻 代码实现(Java)
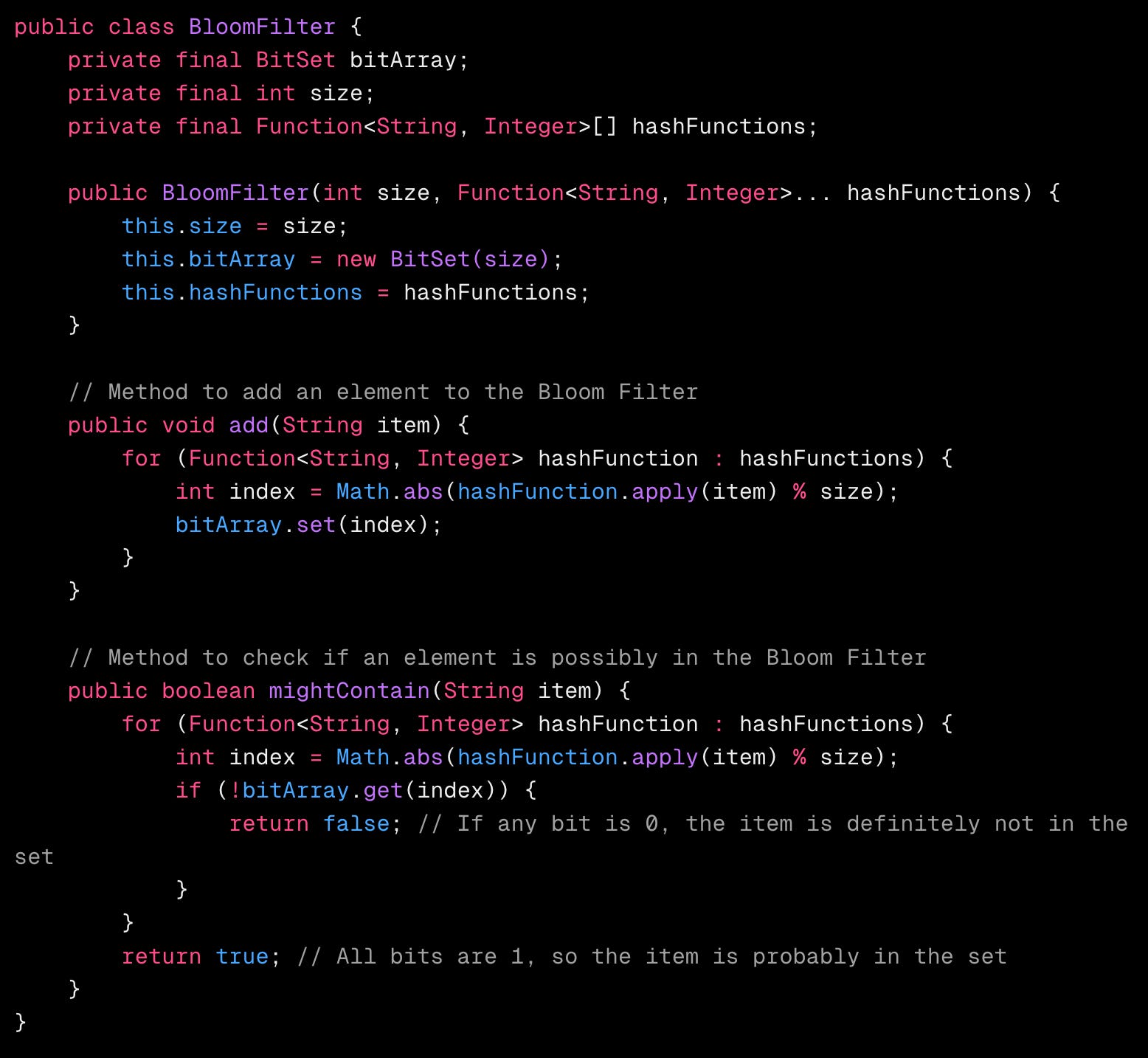
解释
-
BitSet :Java 的
BitSet用于位数组,以高效地存储和操作位。 -
哈希函数 :代码使用了两个简单的哈希函数。你可以添加更复杂的函数以获得更好的分布。
-
add(String item) :此方法接收一个项目,应用每个哈希函数,并在位数组中设置相应的位。
-
mightContain(String item) :此方法通过测试所有相应的位是否为 1 来检查一个项目是否可能在集合中。
-
如果任何位为 0,则该项目 肯定不在集合中 。
-
如果所有位都是 1,则该项目 可能在集合中 (有小概率的误报)。
-
订阅以每周接收新文章。
🌎 布隆过滤器的实际应用
布隆过滤器广泛应用于需要空间效率和速度的实际应用中,并且可以接受偶尔的误报。
以下是一些常见的布隆过滤器应用场景:
1. 网页缓存
问题 :网页服务器经常缓存频繁访问的页面或资源以提高响应时间。然而,随着缓存的增长,检查每个资源的缓存可能变得昂贵且缓慢。
解决方案 :布隆过滤器可以用于快速检查一个 URL 是否可能在缓存中。当请求到达时,首先检查布隆过滤器。如果布隆过滤器指示 URL “可能在缓存中”,则执行缓存查找。
如果它指示 URL “肯定不在缓存中”,服务器将跳过缓存查找并从主存储中获取资源,从而节省时间和资源。
2. 电子邮件系统中的垃圾邮件过滤
问题 :电子邮件系统需要过滤掉垃圾邮件,而不必不断检查庞大的垃圾邮件数据库。
解决方案 :布隆过滤器可以存储已知垃圾邮件地址的哈希。当新邮件到达时,布隆过滤器检查发件人的地址是否可能在垃圾邮件列表中。
这使电子邮件系统能够快速确定邮件是可能是垃圾邮件还是合法邮件。
3. 数据库
问题 :数据库,尤其是分布式数据库,通常需要在访问或修改数据之前检查一个键是否存在。直接在数据库中对每个键执行这些检查可能很慢。
解决方案 :许多数据库,如 Cassandra 、 HBase 和 Redis ,使用布隆过滤器来避免对不存在的键进行不必要的磁盘查找。布隆过滤器快速检查一个键是否可能存在。如果布隆过滤器指示“不存在”,则可以跳过数据库查找。
4. 内容推荐系统
问题 :推荐系统,如流媒体服务使用的系统,需要避免推荐用户已经消费过的内容。
解决方案 :布隆过滤器可以跟踪每个用户之前观看或互动过的内容。在生成新推荐时,布隆过滤器快速检查一个项目是否可能已经被消费。
5. 社交网络好友推荐
问题 :像 Facebook 或 LinkedIn 这样的社交网络向用户推荐好友或连接,但需要避免推荐已经是好友的人。
解决方案 :布隆过滤器用于存储每个用户现有连接的列表。在建议新朋友之前,可以检查布隆过滤器以确保用户尚未与他们连接。
🛑 布隆过滤器的局限性
1. 误报
布隆过滤器可能产生误报,这意味着它们可能错误地指示一个元素存在于集合中,而实际上并不存在。
例子: 考虑一个不存在的键被检查布隆过滤器的场景。如果所有哈希函数映射到的位已经设置为
1,过滤器错误地信号该键存在。
这样的误报可能导致不必要的处理或对数据的错误假设。
例如, 在数据库系统中,这可能触发不必要的缓存查找或浪费尝试获取实际上不存在的数据。
通过选择一个最佳大小的位数组和适当数量的哈希函数,可以减少误报的可能性,但它们永远无法完全消除。
2. 不支持删除
标准布隆过滤器不支持元素删除。一旦通过添加元素将位设置为 1,就无法取消设置,因为其他元素可能也依赖于该位。
这一限制使得布隆过滤器不适合频繁添加和删除元素的动态集合。
像 Counting Bloom Filter 这样的变体可以通过使用计数器而不是位来允许删除,但这需要更多的内存。
3. 仅限于集合成员查询
布隆过滤器专门设计用于回答集合成员查询。它们不提供有关集合中实际元素的信息,也不支持超出基本成员检查的复杂查询或操作。
例子 :如果你需要知道一个元素的详细信息(例如,用户 ID 的完整信息),你需要除了布隆过滤器之外的其他数据结构。
4. 不适合精确集合成员
布隆过滤器是概率性的,这意味着它们不能提供确定的“是”答案(只能提供“可能是”或“肯定不是”)。
对于需要精确成员信息的应用,布隆过滤器不适合。应使用其他数据结构,如哈希表或平衡树。
5. 易受哈希碰撞影响
随着布隆过滤器中元素数量的增加,哈希碰撞的可能性也增加。多个元素可能最终设置或依赖于相同的位,从而增加误报。
随着哈希碰撞的积累,过滤器的有效性降低。在高负载因子下,过滤器可能表现不佳并变得不可靠。
使用额外的哈希函数可以帮助减少碰撞,但增加哈希函数的数量也会增加复杂性和内存需求。
✅ 结论
总之,布隆过滤器是一种用于空间高效集合成员测试的强大工具,具有广泛的应用范围。虽然由于可能的误报,它们可能不适合所有应用,但在空间有限且可接受小错误率的场景中,它们表现出色。
希望你喜欢阅读这篇文章。
如果你觉得这篇文章有价值,请点赞 ❤️ 并考虑订阅以每周获取更多此类内容。
如果你有任何问题或建议,请留言。
这篇文章是公开的,所以请随意分享。
免费订阅以每周接收新文章。
查看我的 YouTube 频道 以获取更深入的内容。
查看我的 GitHub 仓库 以获取免费的面试准备资源。
希望你有美好的一天!
再见,
Ashish
文章来源:What are Bloom Filters and Where are they Used?
关键问题与行动计划
关键问题 1: 如何利用布隆过滤器技术提升数据存储和检索的效率,特别是在大数据环境下?
行动计划:
- 技术调研:研究团队将深入分析布隆过滤器在不同领域(如数据库、缓存系统、推荐系统等)的应用案例,评估其在大数据环境下的实际效果和潜在改进空间。
- 原型开发:数据团队将开发一个基于布隆过滤器的原型系统,模拟其在特定应用场景(如电商推荐或社交网络)中的表现,以验证其在数据存储和检索效率上的提升。
关键问题 2: 布隆过滤器在反垃圾邮件和内容推荐系统中的应用效果如何?
行动计划:
- 案例分析:研究团队将收集并分析现有反垃圾邮件系统和内容推荐系统中布隆过滤器的应用案例,评估其在减少误判和提升用户体验方面的效果。
- 用户调研:数据团队将通过用户反馈和行为分析,评估布隆过滤器在实际应用中的表现,特别是其对用户满意度和系统性能的影响。
关键问题 3: 布隆过滤器的局限性如何影响其在动态数据集中的应用?
行动计划:
- 局限性研究:研究团队将对布隆过滤器的局限性(如假阳性、无法删除等)进行深入研究,探讨这些局限性在动态数据集中的具体影响,并寻找可能的解决方案或替代技术。
- 竞争技术分析:数据团队将分析市场上其他数据结构(如计数布隆过滤器、哈希表等)的优缺点,评估它们在动态数据集中的应用潜力,以便为投资决策提供参考。
请告诉我们你对此篇总结的改进建议,如存在内容不相关、低质、重复或评分不准确,我们会对其进行分析修正