ONE SENTENCE SUMMARY:
现代大型语言模型(LLM)的训练方法已从单一的预训练扩展到包括后训练,涵盖了多种新技术和方法。
MAIN POINTS:
- LLM的训练流程现在包括预训练和后训练两个阶段。
- 四个主要模型展示了不同的预训练和后训练方法。
- 数据质量和多阶段训练在模型性能中起着关键作用。
TAKEAWAYS:
- 预训练和后训练的多样化方法有助于提升LLM性能。
- 数据过滤和合成数据在训练中变得越来越重要。
- 不同模型的后训练策略显示出对用户偏好的重视。
大型语言模型(LLM)的发展已经走过了漫长的道路,从早期的GPT模型到今天复杂的开源权重LLM。最初,LLM的训练过程仅关注预训练,但现在已经扩展到包括预训练和后训练。后训练通常包括监督指令微调和对齐,这一方法由ChatGPT推广。
自ChatGPT首次发布以来,训练方法已经发生了变化。在本文中,我将回顾最近几个月在预训练和后训练方法方面的最新进展。
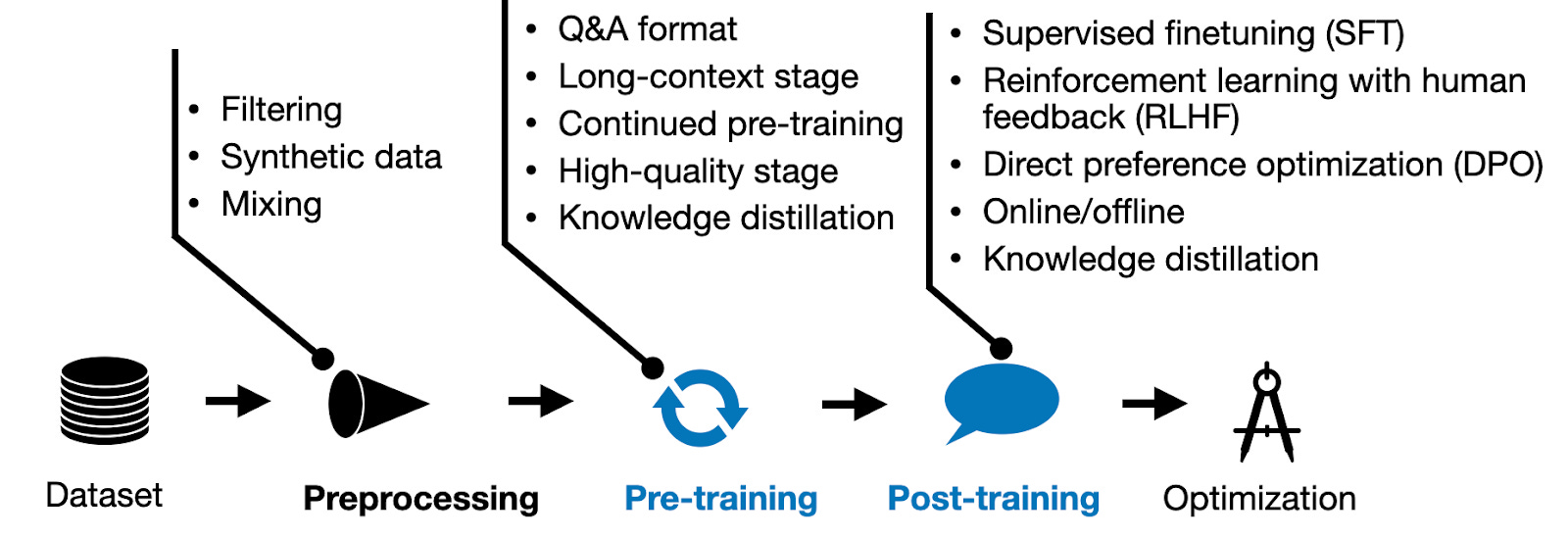
每个月都有数百篇LLM论文提出新技术和方法。然而,了解哪些方法在实践中真正有效的最佳方式之一是查看最近的最先进模型的预训练和后训练流程。幸运的是,过去几个月发布了四个主要的新LLM,并附有相对详细的技术报告。
在本文中,我将重点介绍以下模型的预训练和后训练流程:
-
阿里巴巴的Qwen 2
-
苹果智能基础语言模型
-
谷歌的Gemma 2
-
Meta AI的Llama 3.1
这些模型是根据其在arXiv.org上发布的技术论文的发布日期排序的,这也恰好与它们的字母顺序一致。
本文是我在业余时间和周末创作的一个热情项目。如果你觉得它有价值并希望支持我的工作,请考虑购买我的书并推荐给你的同事。你在亚马逊上的评论也将不胜感激!

-
构建大型语言模型(从头开始) 是一本专注于用PyTorch从头开始编写LLM的书,涵盖了从预训练到后训练的所有内容——这可能是理解LLM的最佳方式。
-
机器学习Q和AI 是一本适合已经熟悉基础知识的读者的好书;它深入探讨了中级和高级概念,涵盖了深度神经网络、视觉变换器、多GPU训练范式、LLM等许多内容。
-
使用PyTorch和Scikit-Learn进行机器学习 是一本全面的机器学习、深度学习和AI指南,提供了理论和实际代码的良好平衡。它是任何新手入门的理想起点。
1. 阿里巴巴的Qwen 2
让我们从 Qwen 2 开始,这是一个非常强大的LLM模型家族,与其他主要LLM竞争。然而,出于某种原因,它不如Meta AI、Microsoft和Google的开源权重模型受欢迎。
1.1 Qwen 2概述
在查看 Qwen 2技术报告 中讨论的预训练和后训练方法之前,让我们简要总结一些核心规格。
Qwen 2 模型有 5 种版本。包括 4 种常规(密集型)LLM,参数规模分别为 5 亿、15 亿、70 亿和 720 亿。此外,还有一种参数为 570 亿的专家混合模型,其中同时激活的参数为 140 亿。(由于这次的重点不在于架构细节,我不会过多讨论专家混合模型;简而言之,这类似于 Mistral AI 的 Mixtral,但它有更多的活跃专家。欲了解高层次概述,请参阅我的 Mixtral Architecture 部分,以及 Model Merging, Mixtures of Experts, and Towards Smaller LLMs 文章 。)
Qwen 2 LLMs 的一个突出特点是其在 30 种语言中的良好多语言能力。它们还拥有惊人的 151,642 个词汇量(作为参考,Llama 2 使用 32k 词汇量,Llama 3.1 使用 128k 词汇量);根据经验,词汇量增加 2 倍会使输入词汇量减少 2 倍,从而使 LLM 能够在相同输入中容纳更多词汇。这对于多语言数据和编程尤其有帮助,因为它可以覆盖标准英语词汇之外的单词。
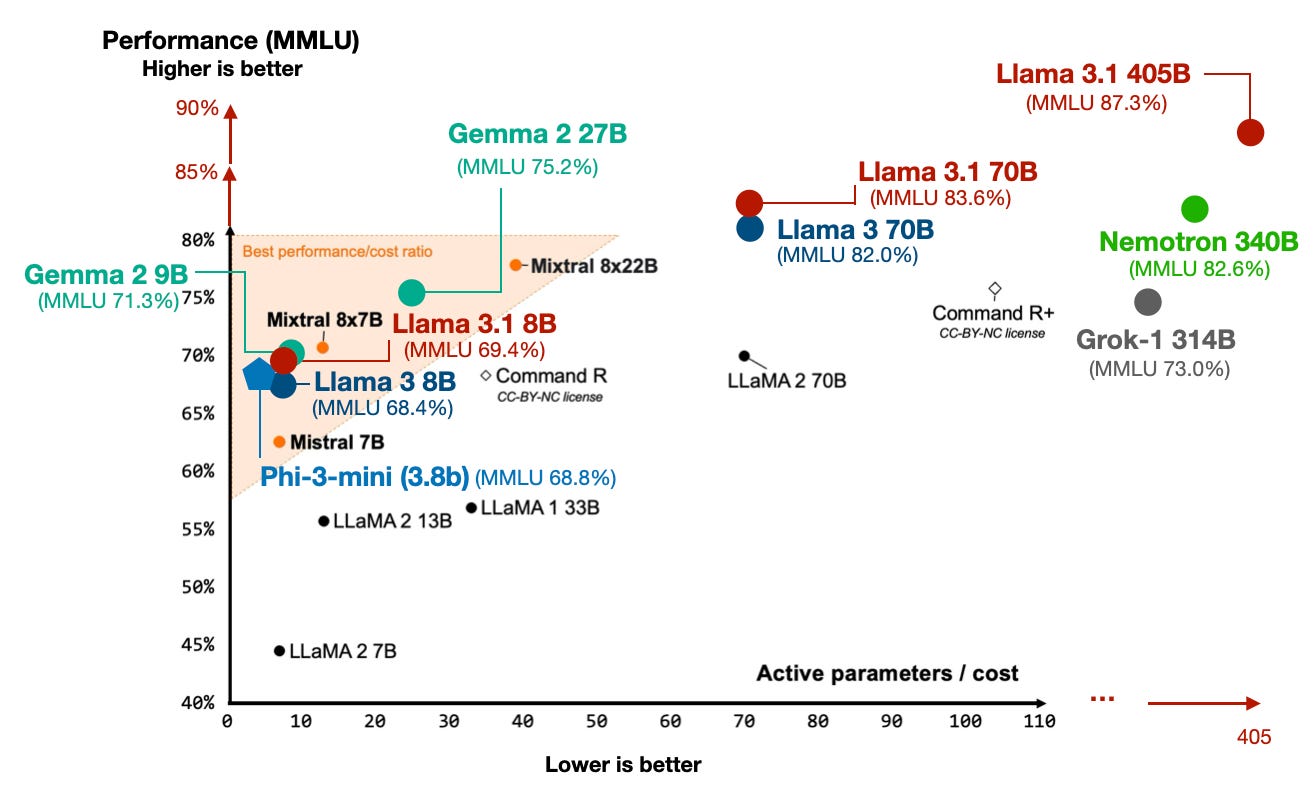
下面是与其他 LLMs 的简要 MMLU 基准测试比较。(请注意,MMLU 是一种多项选择基准测试,因此有其局限性;然而,它仍然是报告 LLM 性能的最流行方法之一。)
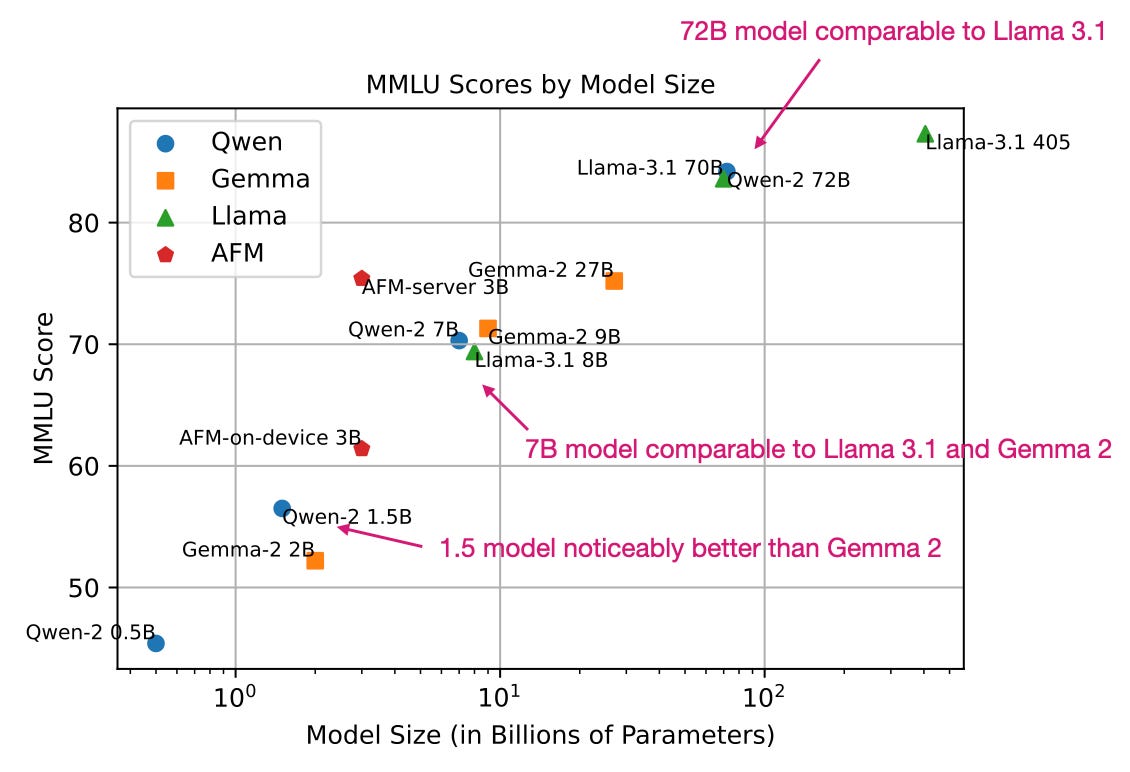
(如果你是 MMLU 新手,我在 最近的演讲中第 46:05 分钟 简要讨论了它。)
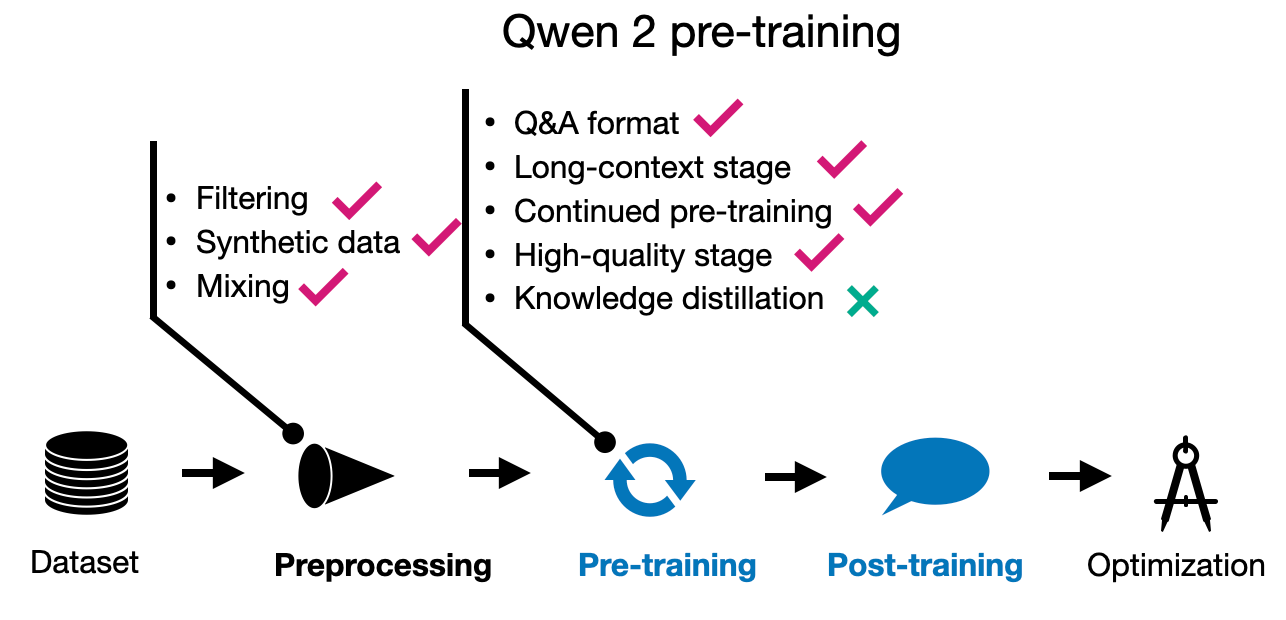
1.2 Qwen 2 预训练
Qwen 2 团队在 7 万亿训练词汇上训练了 15 亿、70 亿和 720 亿参数模型,这是一个合理的规模。相比之下,Llama 2 模型在 2 万亿词汇上训练,而 Llama 3.1 模型在 15 万亿词汇上训练。
有趣的是,5 亿参数模型在 12 万亿词汇上训练。然而,研究人员没有在更大的 12 万亿词汇数据集上训练其他模型,因为他们在训练过程中没有观察到任何改进,额外的计算成本也不值得。
其中一个重点领域是改进数据过滤管道以去除低质量数据,并增强数据混合以增加数据多样性——这是我们在稍后检查其他模型时会再次讨论的主题。
有趣的是,他们还使用 Qwen 模型(尽管他们没有具体说明,我假设他们指的是上一代 Qwen 模型)来合成额外的预训练数据。预训练涉及“多任务指令数据……以增强上下文学习和指令跟随能力。”
此外,他们在两个阶段进行训练:常规预训练和长上下文训练。后者在预训练结束阶段将上下文长度从 4,096 增加到 32,768 个词汇,使用“高质量、冗长的数据。”
(不幸的是,技术报告的另一个主题是关于数据集的细节很少,所以如果我的写作看起来不太详细,那是因为缺乏公开的可用信息。)
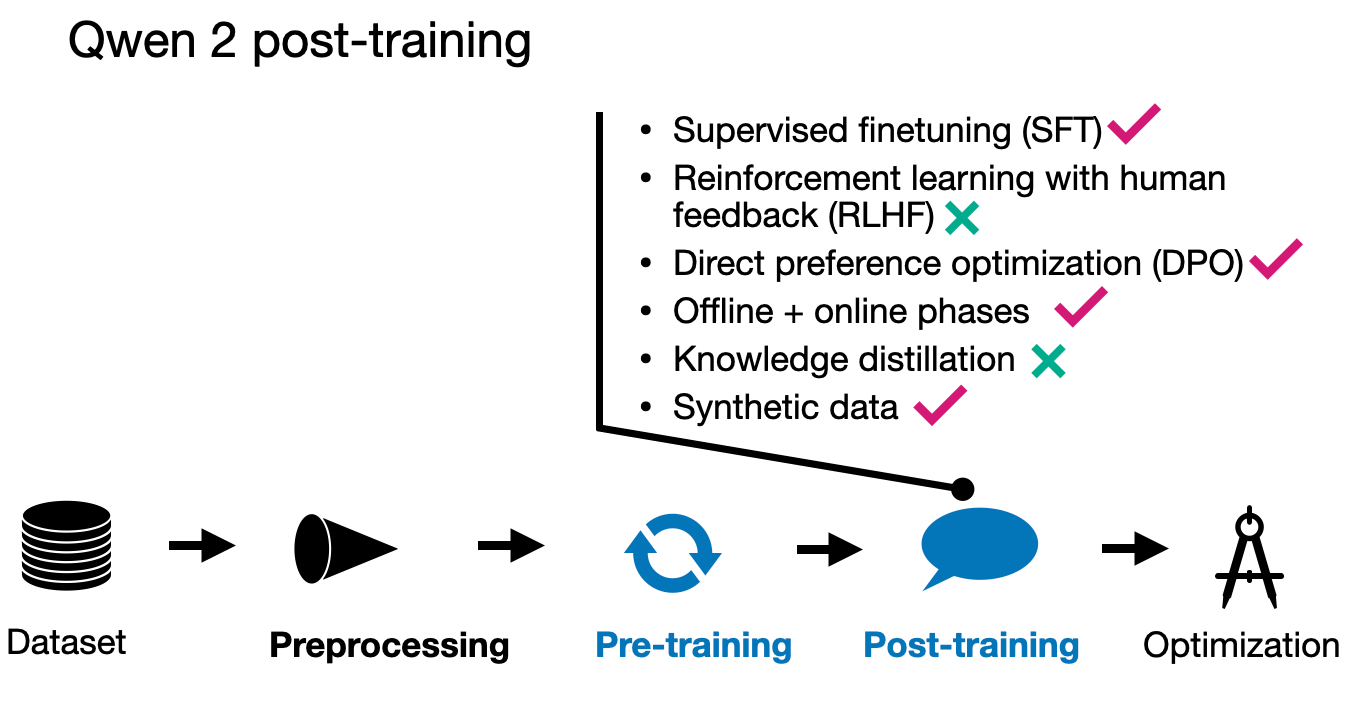
1.3 Qwen 2 后训练
Qwen 2 团队采用了流行的两阶段后训练方法,首先进行监督指令微调(SFT),在 500,000 个示例上进行了 2 个周期。这一阶段旨在提高模型在预定场景中的响应准确性。
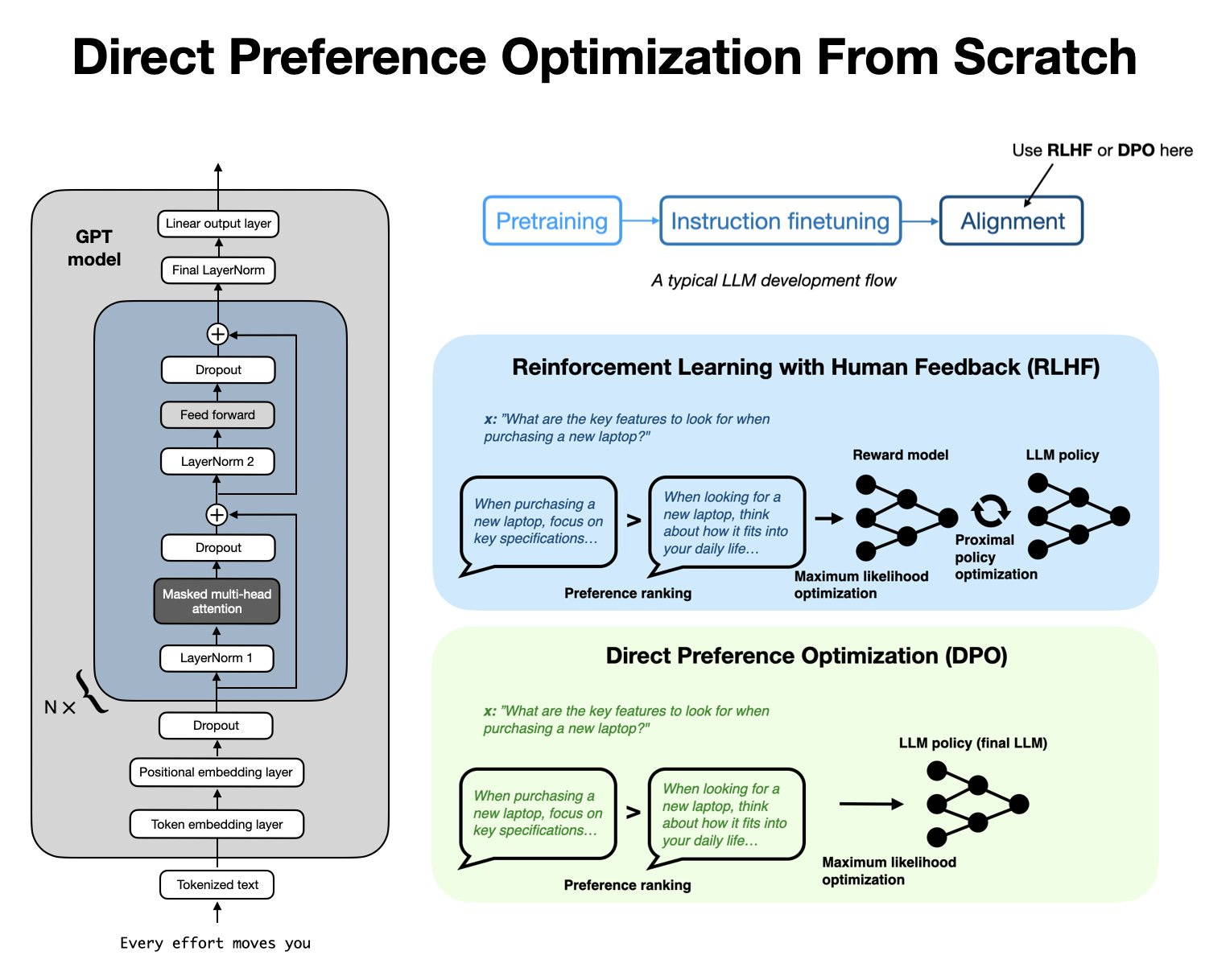
在 SFT 之后,他们使用直接偏好优化(DPO)来使 LLM 与人类偏好对齐。(有趣的是,他们的术语中称之为从人类反馈中进行强化学习,RLHF。)正如我几周前在《LLM 预训练和评估奖励模型的技巧》一文中讨论的那样,SFT+DPO 方法由于比其他方法(如使用 PPO 的 RLHF)更易于使用,目前似乎是最流行的偏好调优策略。(如果你想了解 DPO 的工作原理,我最近从头开始实现了它。)
对齐阶段本身也分为两个阶段。首先在现有数据集上使用 DPO(离线阶段)。其次,使用奖励模型形成偏好对(在线)。在这里,模型在训练期间生成多个响应,奖励模型选择优化步骤中“实时”生成的首选响应。这通常也被称为“拒绝采样”。
为了构建数据集,他们使用了现有的语料库,并通过人工标注来确定 SFT 的目标响应,并识别 DPO 所需的首选和被拒绝的响应。研究人员还合成了人工注释的数据。
此外,团队使用 LLM 生成专门针对“高质量文学数据”的指令-响应对,以创建高质量的问答对进行训练。
1.4 结论
Qwen 2 是一个相对有能力的模型,与早期版本的 Qwen 类似。在 2023 年 12 月参加 NeurIPS LLM 效率挑战赛时,我记得大多数获胜的方法都涉及 Qwen 模型。
关于 Qwen 2 的训练流程,值得注意的是合成数据被用于预训练和后训练。此外,数据集过滤(而不是尽可能多地收集数据)是 LLM 训练中的一个显著趋势。在这里,我会说,更多的数据是更好的,但前提是它们符合某些质量标准。
从头开始使用直接偏好优化对齐 LLM
直接偏好优化(DPO)已成为将 LLM 更紧密地与用户偏好对齐的首选方法之一,这也是你将在本文中经常看到的内容。如果你想了解它是如何工作的,我在这里从头开始编写了代码:
2. 苹果的 Apple Intelligence Foundation 语言模型(AFM)
我很高兴在 arXiv.org 上看到 Apple 的另一篇技术论文,概述了他们的模型训练。这是一个意外但绝对积极的惊喜!
2.1 AFM 概述
在 Apple Intelligence Foundation 语言模型 论文中,研究团队概述了两种主要模型的开发,这些模型设计用于 Apple 设备上的“Apple Intelligence”环境。为了简洁起见,这些模型将在本节中简称为 AFM,即“Apple Foundation Models”。
具体来说,论文描述了两种版本的 AFM:一种是用于手机、平板电脑或笔记本电脑的 30 亿参数的设备模型,另一种是更强大的 30 亿参数的服务器模型。
这些模型是为聊天、数学和编码任务开发的,尽管论文没有讨论任何与编码相关的训练和能力。
与 Qwen 2 类似,AFM 也是密集型 LLM,并未采用专家混合方法。
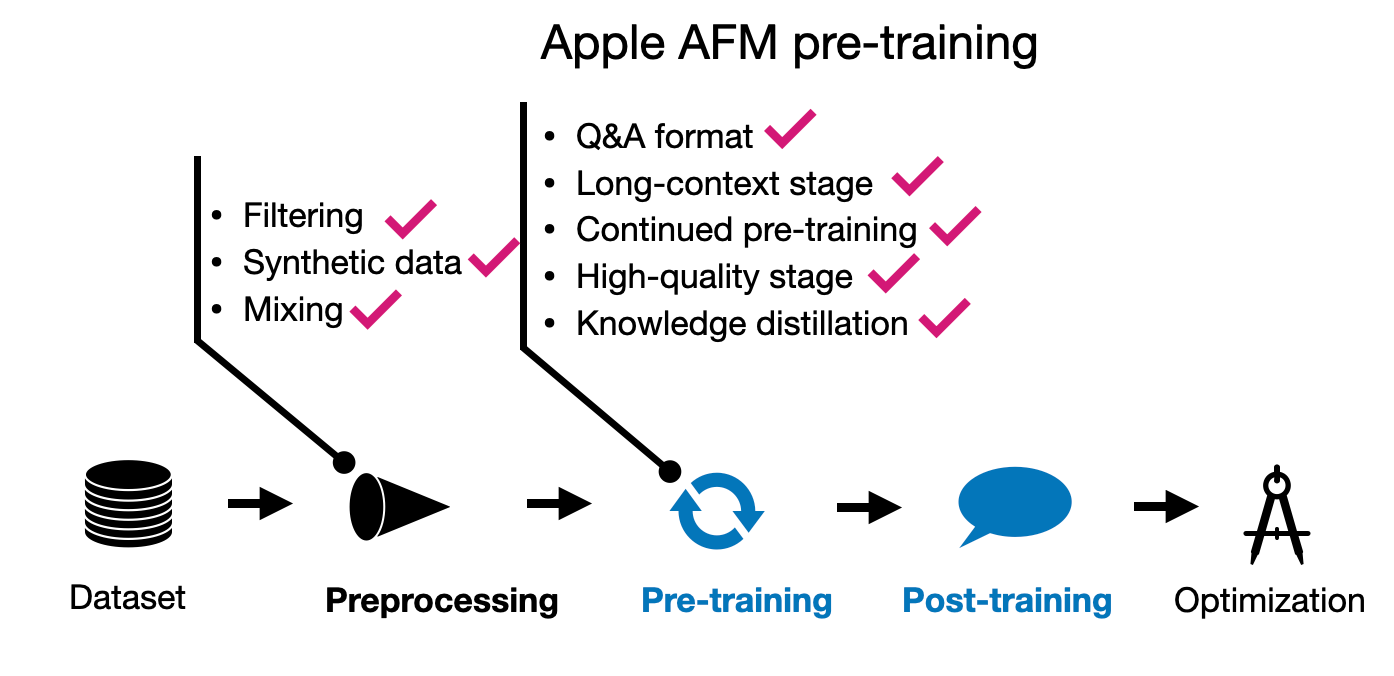
2.2 AFM 预训练
我要向研究人员致以两大赞赏。首先,除了使用公开可用的数据和出版商许可的数据外,他们还尊重网站上的 robots.txt 文件,并避免爬取这些网站。其次,他们还提到对基准数据进行了去污染处理。
为了强化 Qwen 2 论文的一个要点,研究人员提到质量比数量更重要。(设备模型的词汇量为 49k 词元,服务器模型的词汇量为 100k 词元,这些词汇量明显小于 Qwen 2 模型的 150k 词元词汇量。)
有趣的是,预训练不是分为 2 个阶段,而是分为 3 个阶段进行的!
-
核心(常规)预训练
-
继续预训练,其中网络爬取的(较低质量)数据被降低权重;数学和代码数据被提高权重
-
通过更长序列数据和合成数据进行上下文延长

让我们详细看看这三个步骤。
2.2.1 预训练 I: 核心预训练
核心预训练描述了Apple预训练管道中的第一个预训练阶段。这类似于常规预训练,其中AFM服务器模型在6.3万亿个标记、4096批次大小和4096标记序列长度上进行了训练。这与Qwen 2模型非常相似,后者在7万亿个标记上进行了训练。
然而,对于AFM设备模型来说,情况变得更有趣了,它是从一个较大的64亿参数模型中蒸馏和剪枝而来的(从头开始训练,如前一段中描述的AFM服务器模型。请注意,AFM服务器和AFM设备都是30亿参数模型。)
关于蒸馏过程的细节不多,除了“通过用真实标签和教师模型的top-1预测的凸组合(教师标签占0.9权重)替换目标标签来使用蒸馏损失。”
我觉得知识蒸馏在LLM预训练中变得越来越普遍和有用(Gemma-2也使用了它)。我计划有一天详细介绍它。目前,这里是一个关于这个过程如何在高层次上工作的简要概述。
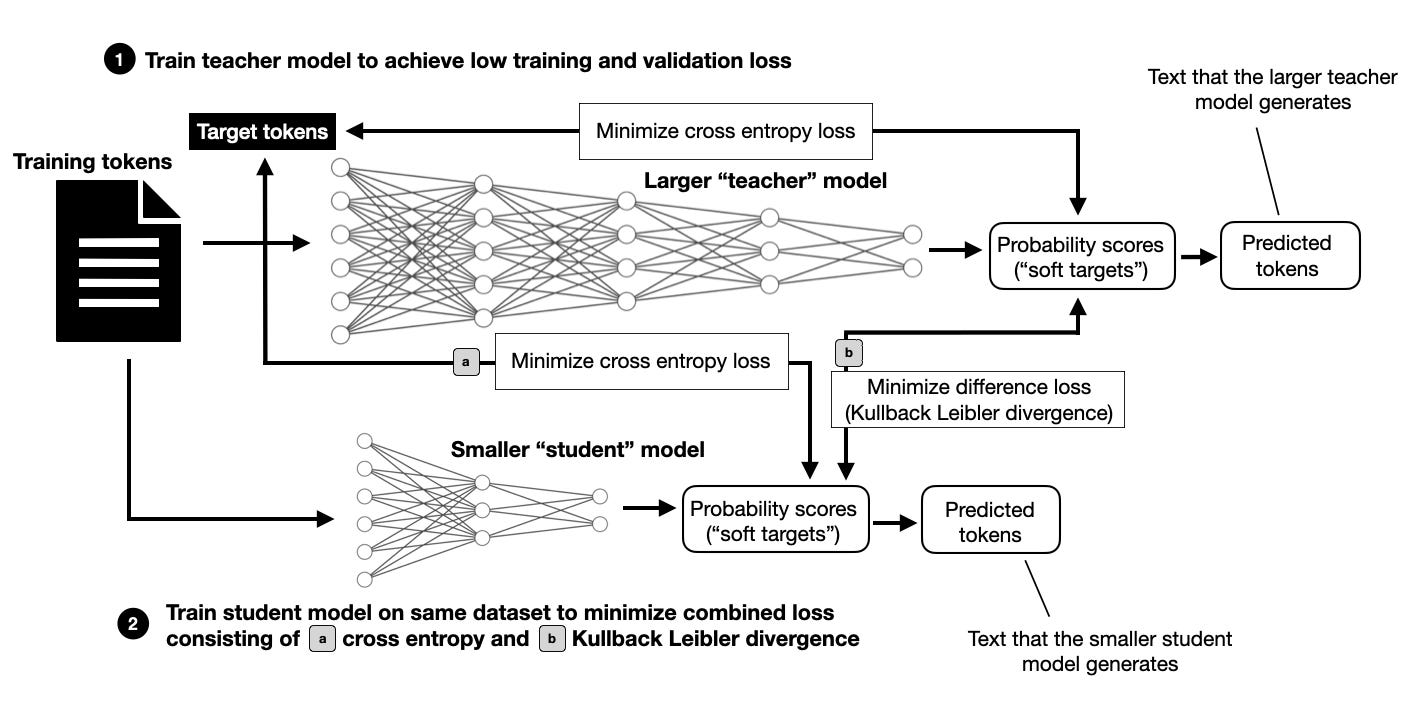
如上图所示,知识蒸馏仍然涉及在原始数据集上进行训练。然而,除了数据集中的训练标记外,要训练的模型(称为学生)还会从较大的(教师)模型中接收信息,这提供了比不使用知识蒸馏训练时更丰富的信号。缺点是你必须:1)首先训练较大的教师模型,2)使用较大的教师模型计算所有训练标记的预测。这些预测可以提前计算(这需要大量存储空间)或在训练期间计算(这可能会减慢训练过程)。
2.2.2 预训练 II: 持续预训练
持续预训练阶段包括一个小的上下文长度扩展步骤,从4,096个标记增加到8,192个标记,数据集由1万亿个标记组成(核心预训练集大五倍)。主要重点是使用高质量的数据混合进行训练,特别强调数学和代码。
有趣的是,研究人员发现蒸馏损失在这种情况下并没有带来好处。
2.2.3 预训练 III: 上下文长度扩展
第三个预训练阶段仅涉及1000亿个标记(第二阶段标记数量的10%),但代表了更显著的上下文长度扩展到32,768个标记。为此,研究人员使用合成的长上下文问答数据扩充了数据集。
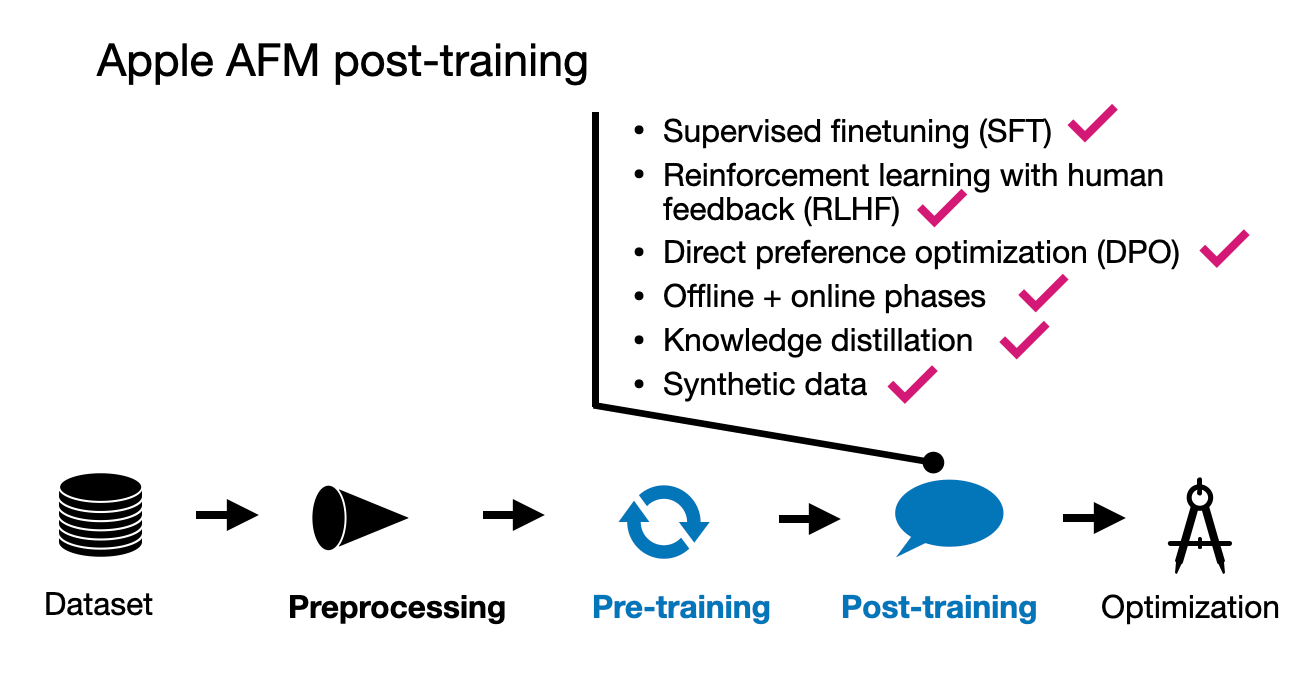
2.3 AFM后训练
苹果在后训练过程中采取了与预训练同样全面的方法。他们利用了人工标注和合成数据,强调数据质量优先于数量。有趣的是,他们没有依赖预定的数据比例,而是通过多次实验微调数据混合,以达到最佳平衡。
后训练阶段包括两个步骤:监督指令微调,随后进行多轮人类反馈的强化学习(RLHF)。
这一过程中一个特别值得注意的方面是苹果在RLHF阶段引入了两种新算法:
-
教师委员会拒绝采样微调(iTeC)
-
镜像下降策略优化的RLHF
鉴于本文篇幅较长,我不会详细讨论这些方法的技术细节,但这里有一个简要概述:
iTeC算法结合了拒绝采样和多种偏好调优技术——具体来说是SFT、DPO、IPO和在线RL。苹果没有依赖单一算法,而是分别使用每种方法独立训练模型。这些模型生成的响应由人类评估并提供偏好标签。这些偏好数据被用来在RLHF框架中迭代训练奖励模型。在拒绝采样阶段,一个模型委员会生成多个响应,由奖励模型选择最佳响应。
这种基于委员会的方法相当复杂,但应该相对可行,特别是考虑到所涉及的模型相对较小(大约3亿参数)。如果要在更大规模的模型上实施这种委员会方法,如Llama 3.1中的70B或405B参数模型,肯定会更具挑战性。
至于第二种算法,镜像下降策略优化的RLHF,它被选择是因为它比常用的PPO(近端策略优化)更有效。
2.4 结论
苹果在预训练和后训练方面的方法相对全面,可能是因为风险非常高(该模型部署在数百万甚至数十亿设备上)。然而,鉴于这些模型的规模较小,许多技术也变得可行,因为3B模型的规模不到Llama 3.1最小模型的一半。
其中一个亮点是,这不是在RLHF和DPO之间的简单选择;相反,他们使用了多种偏好调优算法组成的委员会。
另一个有趣的点是,他们明确使用了问答数据作为预训练的一部分——这是我在上一篇文章 指令预训练LLMs 中讨论过的。
总的来说,这是一份令人耳目一新的技术报告。
3. 谷歌的Gemma 2
谷歌的Gemma模型最近在 Gemma 2: Improving Open Language Models at a Practical Size 中进行了描述。
在讨论预训练和后训练过程之前,我将提供一些关键事实的概述。
3.1 Gemma 2概述
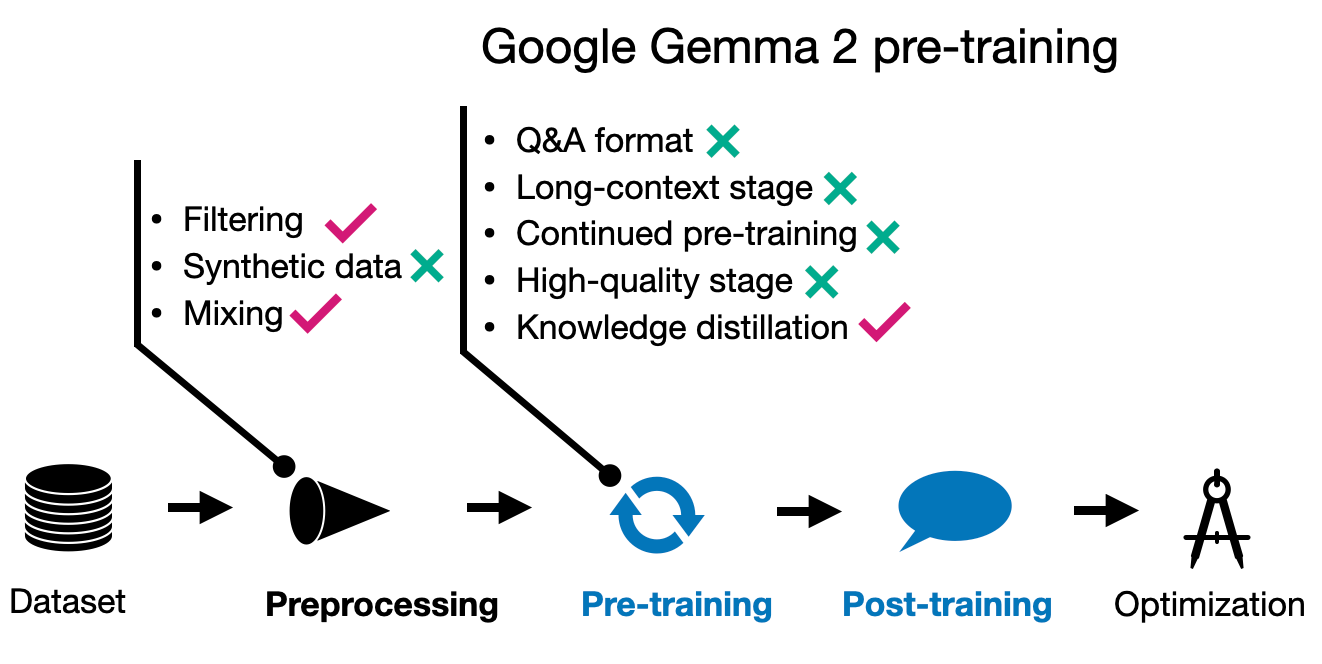
Gemma 2模型有三种规模:2亿、9亿和27亿参数。主要关注点是探索不一定需要增加训练数据集规模的技术,而是开发相对小型和高效的LLM。
值得注意的是,Gemma 2 拥有 256k 词汇量的庞大词汇表。相比之下,Llama 2 使用的是 32k 词汇量的词汇表,而 Llama 3 则有 128k 词汇量的词汇表。
此外,Gemma 2 采用了滑动窗口注意力机制,类似于 Mistral 的早期模型,可能是为了降低内存成本。有关 Gemma 2 架构的更多详细信息,请参阅 我之前文章中的 Gemma 2 部分 。
3.2 Gemma 2 预训练
Gemma 的研究人员认为,即使是小模型也常常训练不足。然而,他们并没有简单地增加训练数据集的大小,而是专注于保持数据质量,并通过其他方法(如知识蒸馏)来实现改进,类似于 Apple 的方法。
虽然 27B 的 Gemma 2 模型是从头开始训练的,但较小的模型是通过类似于 Apple 的知识蒸馏方法进行训练的。
27B 模型在 13 万亿个标记上进行了训练,9B 模型在 8 万亿个标记上进行了训练,而 2B 模型在 2 万亿个标记上进行了训练。此外,类似于 Apple 的方法,Gemma 团队优化了数据混合以提高性能。
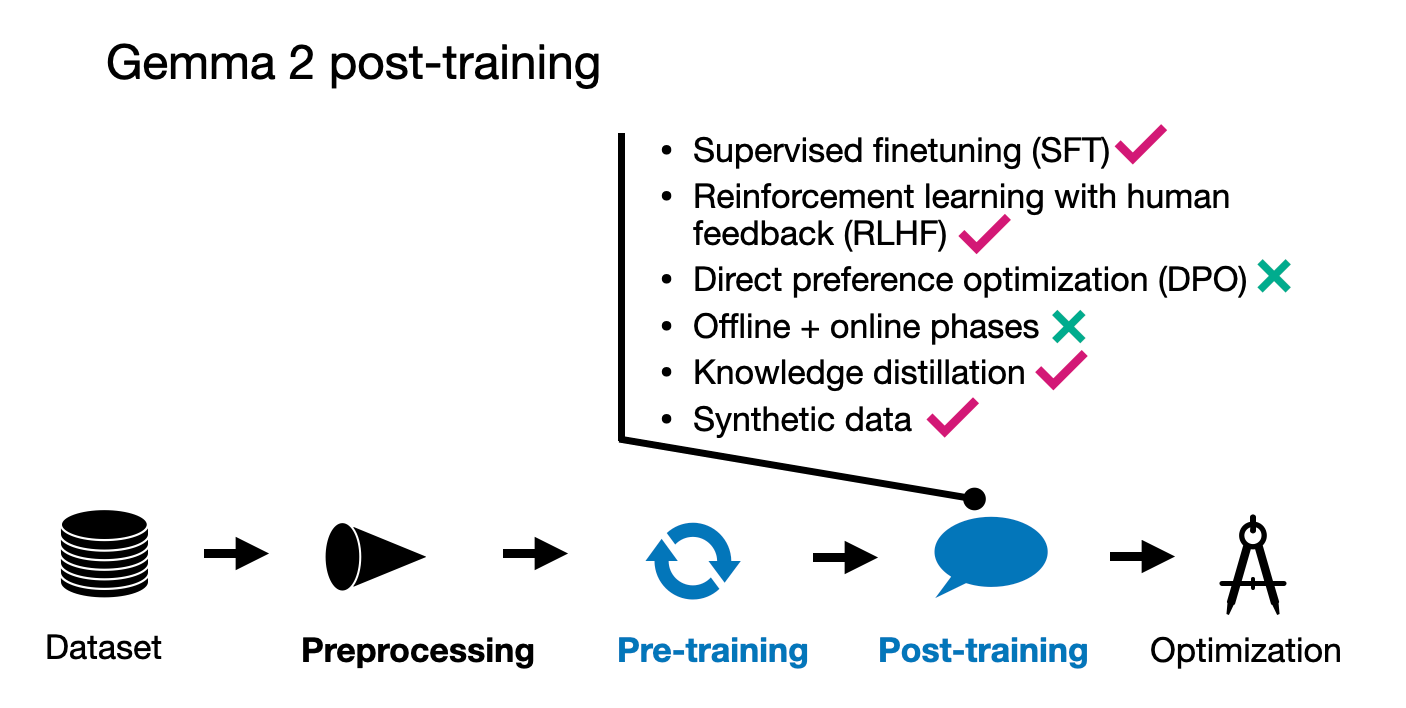
3.3 Gemma 2 后训练
Gemma 模型的后训练过程包括典型的监督微调(SFT)和人类反馈强化学习(RLHF)步骤。
指令数据使用了仅包含英语的提示对,这些提示对是人类生成和合成生成内容的混合。特别有趣的是,响应主要由教师模型生成,并且在 SFT 阶段也应用了知识蒸馏。
在 SFT 之后的 RLHF 方法中,一个有趣的方面是用于 RLHF 的奖励模型比策略(目标)模型大十倍。
Gemma 使用的 RLHF 算法相当标准,但有一个独特的变化:他们通过一种称为 WARP 的方法对策略模型进行平均,这是 WARM(权重平均奖励模型)的后继方法。我在之前的文章 "模型合并、专家混合和走向更小的 LLMs" 中详细讨论了这种方法。
3.4 结论
Gemma 团队似乎在知识蒸馏方面下了很大功夫,他们在预训练和后训练阶段都使用了类似于 Apple 的知识蒸馏方法。有趣的是,他们并没有使用多阶段预训练方法,或者至少在他们的论文中没有详细说明。

4. Meta AI 的 Llama 3.1
Meta 的 Llama LLMs 的新版本总是备受关注。这次发布还附带了一份92页的技术报告: The Llama 3 Herd of Models 。最后但同样重要的是,在本节中,我们将看看上个月发布的第四篇重要模型论文。
4.1 Llama 3.1 概述
除了发布一个巨大的4050亿参数模型外,Meta 还更新了之前的80亿和700亿参数模型,使它们的 MMLU 性能略有提升。
虽然 Llama 3 使用了与其他最新 LLM 类似的组查询注意力机制,但令人惊讶的是,Meta AI 并没有采用滑动窗口注意力和专家混合方法。换句话说,Llama 3.1 看起来非常传统,显然重点在于预训练和后训练,而不是架构创新。
与之前的 Llama 版本类似,权重是公开可用的。此外,Meta 表示他们更新了 Llama 3 的许可证,现在终于可以(允许)使用 Llama 3 进行合成数据生成或知识蒸馏以改进其他模型。
4.2 Llama 3.1 预训练
Llama 3 是在一个庞大的15.6万亿个标记数据集上训练的,这比 Llama 2 的1.8万亿个标记有了大幅增加。研究人员表示,它至少支持八种语言(而 Qwen 2 能处理20种语言)。
Llama 3 的一个有趣方面是其12.8万个词汇量,这是使用 OpenAI 的 tiktoken 分词器开发的。(对于那些对分词器性能感兴趣的人,我在 这里 做了一个简单的基准比较。)
在预训练数据质量控制方面,Llama 3 采用了基于启发式的过滤和基于模型的质量过滤,利用了像 Meta AI 的 fastText 和基于 RoBERTa 的分类器等快速分类器。这些分类器还帮助确定训练过程中使用的数据混合的上下文类别。
Llama 3 的预训练分为三个阶段。第一阶段涉及使用8k上下文窗口的15.6万亿个标记进行标准初始预训练。第二阶段继续预训练,但将上下文长度扩展到128k。最后阶段涉及退火,进一步提高了模型的性能。让我们在下面更详细地了解这些阶段。
4.2.1 预训练 I: 标准(初始)预训练
在他们的训练设置中,他们开始时使用包含400万个标记的批次,每个序列长度为4096。这意味着批次大小约为1024个标记,假设400万这个数字是四舍五入的。在处理了前252百万个标记后,他们将序列长度加倍到8192。在训练过程中,经过2.87万亿个标记后,他们再次将批次大小加倍。
此外,研究人员在整个训练过程中并没有保持数据混合的恒定。相反,他们在训练过程中调整了所使用的数据混合,以优化模型的学习和性能。这种动态的数据处理方法可能有助于提高模型在不同类型数据上的泛化能力。
4.2.2 预训练 II: 持续预训练以延长上下文长度
与其他一次性增加上下文窗口的模型相比,Llama 3.1 的上下文长度延长采用了更为渐进的方法:研究人员通过六个不同阶段将上下文长度从 8,000 个 token 增加到 128,000 个 token。这样的逐步增加可能使模型更平稳地适应更大的上下文。
用于此过程的训练集涉及 8000 亿个 token,占总数据集大小的约 5%。
4.2.3 预训练 III: 在高质量数据上退火
在第三阶段的预训练中,研究人员在一个小但高质量的数据混合上训练模型,他们发现这有助于提高在基准数据集上的性能。例如,在 GSM8K 和 MATH 训练集上退火显著提升了在相应的 GSM8K 和 MATH 验证集上的表现。
在论文的第 3.1.3 节中,研究人员指出退火数据集的大小为 400 亿个 token(占总数据集大小的 0.02%)。然而,在第 3.4.3 节中,他们又指出退火仅在 4000 万个 token(占退火数据的 0.1%)上进行。
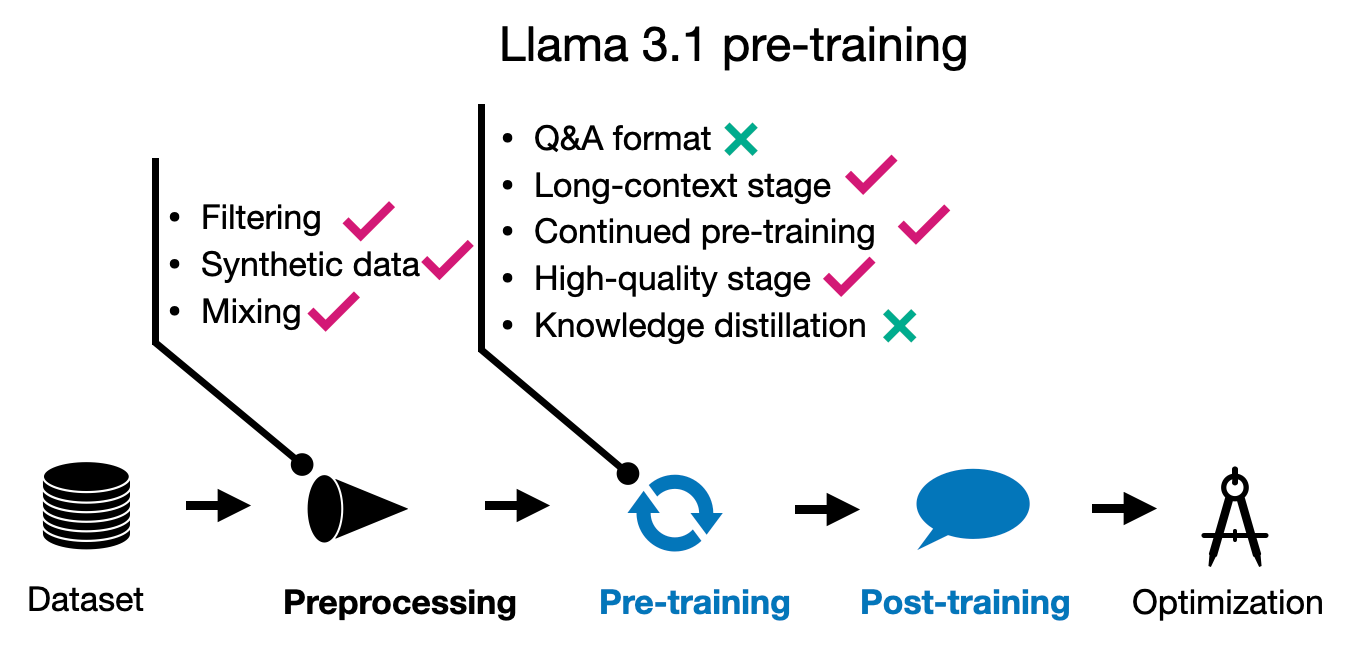
4.3 Llama 3.1 后训练
在后训练过程中,Meta AI 团队采用了一种相对简单的方法,包括监督微调(SFT)、拒绝采样和直接偏好优化(DPO)。
他们观察到,像 RLHF 与 PPO 这样的强化学习算法相比,这些技术更稳定且更易于扩展。值得注意的是,SFT 和 DPO 步骤在多个回合中反复进行,结合了人工生成和合成数据。
在描述进一步的细节之前,他们的工作流程在下图中有所展示。
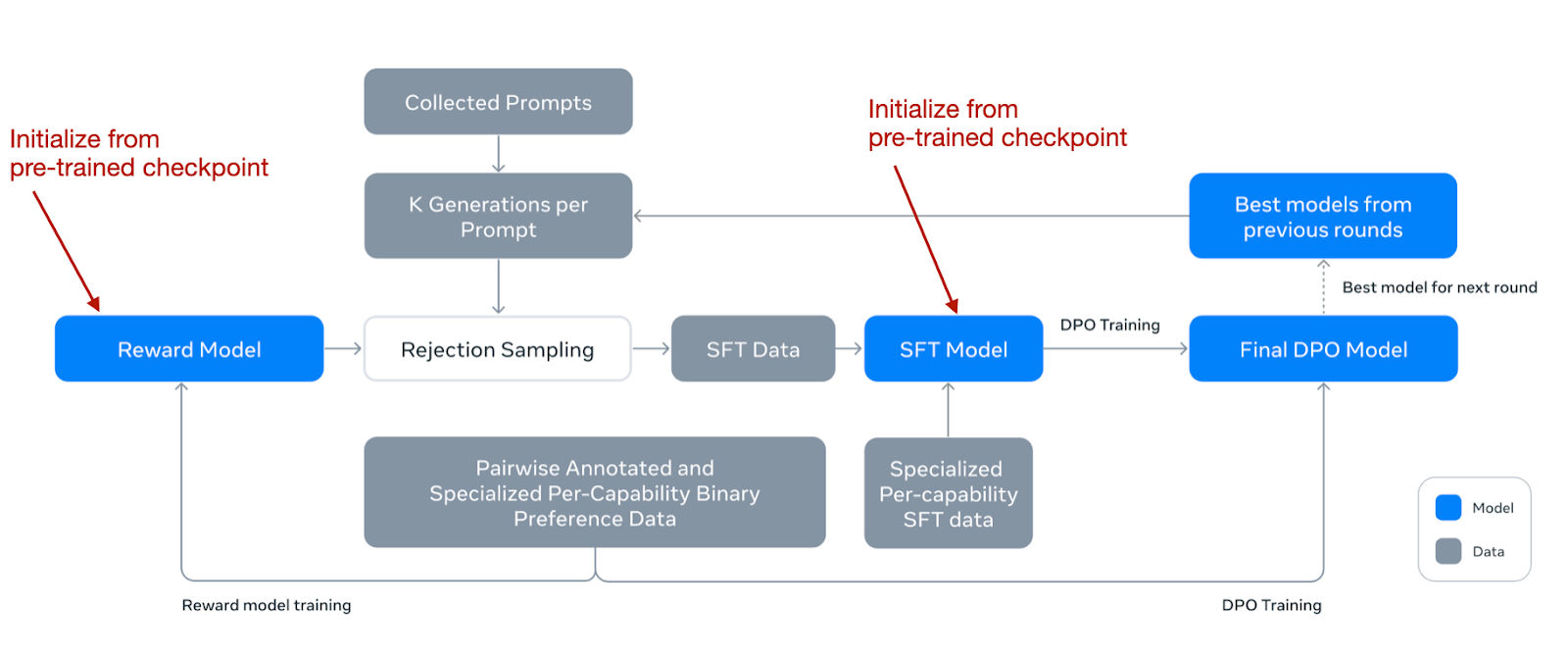
请注意,尽管他们使用了 DPO,他们也开发了一个奖励模型,就像在 RLHF 中所做的那样。最初,他们使用预训练阶段的一个检查点,利用人工注释数据训练奖励模型。然后,这个奖励模型被用于拒绝采样过程,帮助选择适合进一步训练的提示。
在每一轮训练中,他们不仅对奖励模型,还对 SFT 和 DPO 模型应用了模型平均技术。这种平均涉及合并最近和以前模型的参数,以稳定(并提高)性能。
对于那些对模型平均技术的技术细节感兴趣的人,我在之前的文章 模型合并、专家混合和走向更小的 LLMs 的“理解模型合并和权重平均”部分中讨论了这个话题。
总的来说,核心是一个相对标准的 SFT + DPO 阶段。然而,这个阶段在多个回合中反复进行。然后,他们在其中加入了一个用于拒绝采样的奖励模型(类似于 Qwen 2 和 AFM)。他们还使用了类似于 Gemma 的模型平均技术,但不仅仅是针对奖励模型,而是针对所有参与的模型。
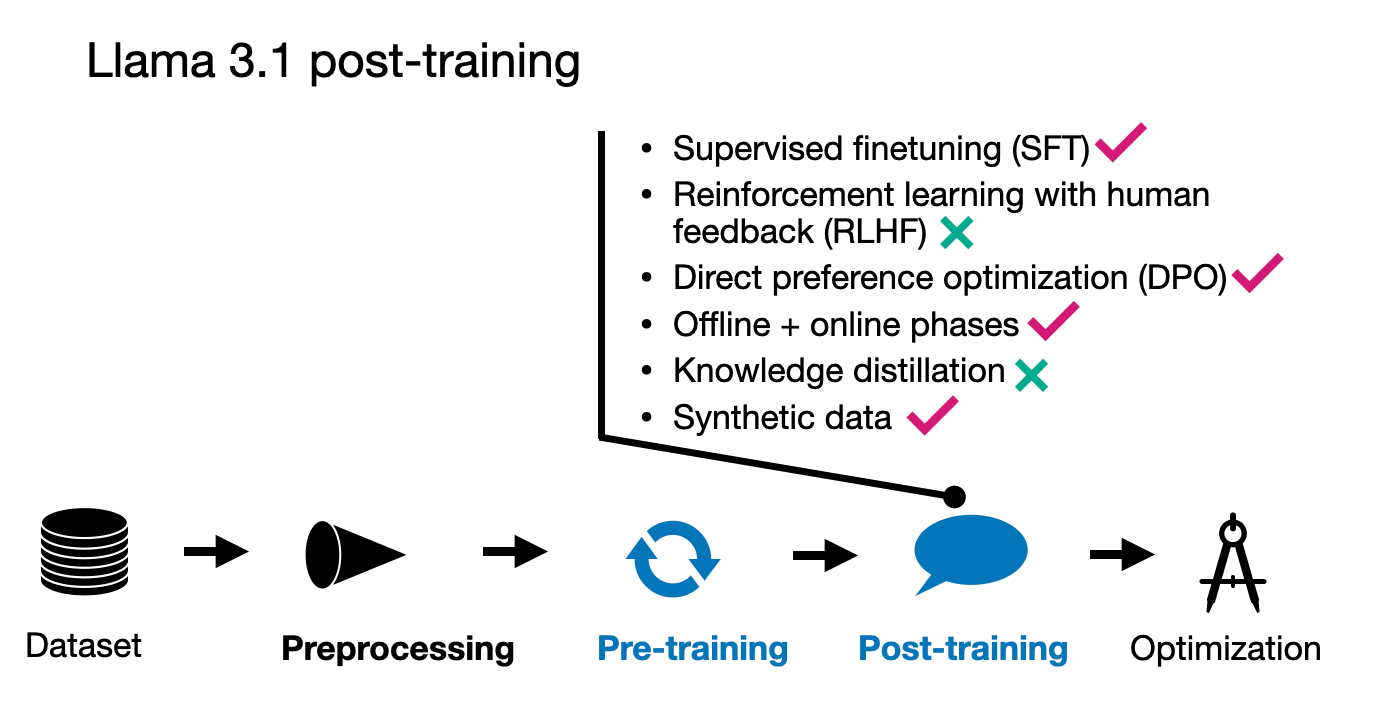
4.4 结论
Llama 3 模型在整体上仍然比较标准,与早期的 Llama 2 模型相似,但也有一些有趣的改进。特别是,Llama 3 使用了一个包含 15 万亿个 token 的大型训练集,这使其与其他模型区分开来。有趣的是,像 Apple 的 AFM 模型一样,Llama 3 也实施了一个三阶段的预训练过程。
与其他最近的大型语言模型相比,Llama 3 没有采用知识蒸馏技术,而是选择了一条更为直接的模型开发路径。在后训练阶段,该模型使用了直接偏好优化(DPO),而不是其他模型中流行的复杂强化学习策略。总体而言,这一选择表明其重点在于通过更简单(但经过验证)的方法来优化 LLM 性能。
5. 主要收获
从本文讨论的四个模型:阿里巴巴的 Qwen 2、Apple 的基础模型(AFM)、Google 的 Gemma 2 和 Meta 的 Llama 3 中,我们能学到什么?
这四个模型在预训练和后训练方面采取了不同的方法。当然,方法论有重叠之处,但没有一个训练管道是完全相同的。在预训练方面,一个共同的特点是所有方法都使用了多阶段的预训练管道,其中一般的核心预训练之后是上下文延长,有时还有高质量退火步骤。下图再次展示了预训练中使用的不同方法。

在后训练方面,各个管道也不尽相同。似乎拒绝采样现在已经成为后训练过程中的一个常见步骤。然而,对于 DPO 或 RLHF,目前还没有形成共识或偏好(无双关意)。

总的来说,没有单一的配方可以开发出高性能的LLM,而是有许多不同的路径。
最后,这四个模型的表现大致相当。不幸的是,其中一些模型尚未进入LMSYS和AlpacaEval排行榜,因此我们还没有直接的比较,除了在MMLU等多项选择基准测试中的得分。
支持Ahead of AI
Ahead of AI是一个个人的激情项目,没有直接的报酬。然而,对于那些希望支持我的人,请考虑购买 我的书 。如果你觉得这些书有见地且有益,请随意推荐给你的朋友和同事。
如果你有几分钟时间,请在 Machine Learning Q and AI 或 Machine Learning with PyTorch and Scikit-Learn 在Amazon上的评论也会非常有帮助!
你的支持意义重大,并且在继续这段旅程中非常有帮助。谢谢!
Build A Large Language Model (From Scratch) , Machine Learning Q And AI , and Machine Learning with PyTorch and Scikit-Learn
文章来源:New LLM Pre-training and Post-training Paradigms
关键问题与行动计划
关键问题 1: 如何评估新一代大型语言模型(LLM)的市场潜力和应用场景?
行动计划:
- 市场需求分析:研究团队将对当前市场上主要的LLM进行分析,识别其应用场景(如教育、医疗、金融等),并评估这些领域的市场需求和潜在增长。
- 竞争对手研究:数据团队将收集和分析主要竞争对手的产品特性、市场表现和用户反馈,以识别新兴LLM的差异化优势和市场切入点。
关键问题 2: 如何利用合成数据提升LLM的训练效率和效果?
行动计划:
- 合成数据策略研究:研究团队将深入探讨合成数据在LLM训练中的应用,包括数据生成方法、质量控制和对模型性能的影响,形成一份详细的研究报告。
- 实验设计与验证:数据团队将设计实验,利用合成数据对比传统数据集的训练效果,评估合成数据在不同模型架构下的表现,以验证其有效性。
关键问题 3: 如何通过优化后训练流程提升LLM的用户体验和响应质量?
行动计划:
- 用户体验调研:研究团队将开展用户访谈和问卷调查,收集用户对现有LLM的使用体验和反馈,识别用户在交互过程中的痛点和需求。
- 后训练流程优化:数据团队将分析不同LLM的后训练流程,特别是监督微调和偏好优化的策略,提出改进建议,以提升模型的响应质量和用户满意度。
请告诉我们你对此篇总结的改进建议,如存在内容不相关、低质、重复或评分不准确,我们会对其进行分析修正