ONE SENTENCE SUMMARY:
系统设计虽然复杂,但理解其基本构建块后,开发者能更好地应对系统设计问题和面试。
MAIN POINTS:
- 理解15个系统设计构建块有助于开发者应对复杂系统。
- 负载均衡器和反向代理提升系统的可用性和安全性。
- 微服务架构支持独立开发和扩展应用程序的不同部分。
TAKEAWAYS:
- 学习基本构建块能简化系统设计过程。
- 使用CDN可加速内容交付,提升用户体验。
- 监控系统确保应用程序的健康和性能。
系统设计可能看起来很复杂,但一旦你理解了它的 基本构建块 以及如何将它们 组合在一起 ,一切就会变得清晰。
在这篇文章中,我们将分解每个开发者都应该了解的系统设计的 15个顶级构建块 。
了解这些将帮助你理解大型系统,并帮助你在下次系统设计面试中回答问题。
📣 更好地设计、开发和管理分布式软件(赞助)

Multiplayer 自动记录你的系统,从高层次的逻辑架构到各个组件、API、依赖关系和环境。非常适合希望加快工作流程并整合技术资产的团队。
1. 负载均衡器
负载均衡器 将传入请求分配到 多个服务器 ,以确保没有单个服务器承受过多负载。它通过在服务器故障时自动重新路由流量来帮助维持 可用性 和 可靠性 。
当你的应用程序超出单个服务器的容量并需要 水平扩展 以维持性能和可用性时,使用它。
类型:
-
第4层负载均衡器: 在传输层操作(例如,TCP,UDP)。
-
第7层负载均衡器: 在应用层操作(例如,HTTP,HTTPS)。
示例: Nginx, HAProxy, AWS ELB
2. 反向代理
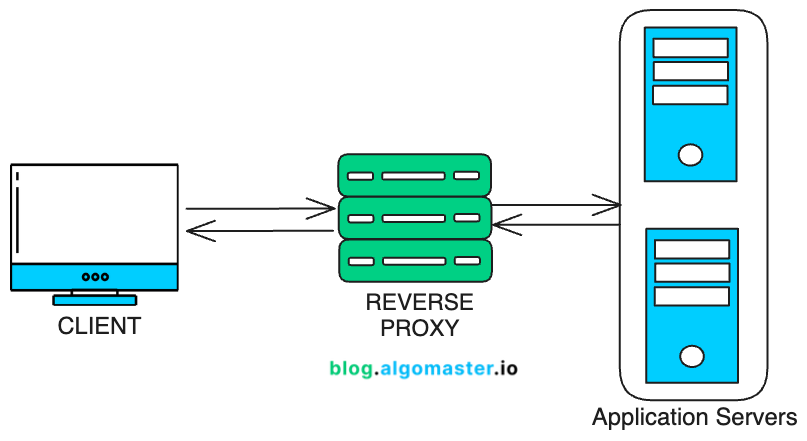
反向代理 是客户端和服务器之间的中介。它将客户端请求转发到合适的后端服务器,然后将服务器的响应返回给客户端。
它通过隐藏后端服务器来 增强安全性 ,并通过缓存来 优化性能 。
例子: Cloudflare 作为网站的反向代理,通过缓存资源和阻止恶意流量来保护和加速内容交付。
3. 域名系统 (DNS)
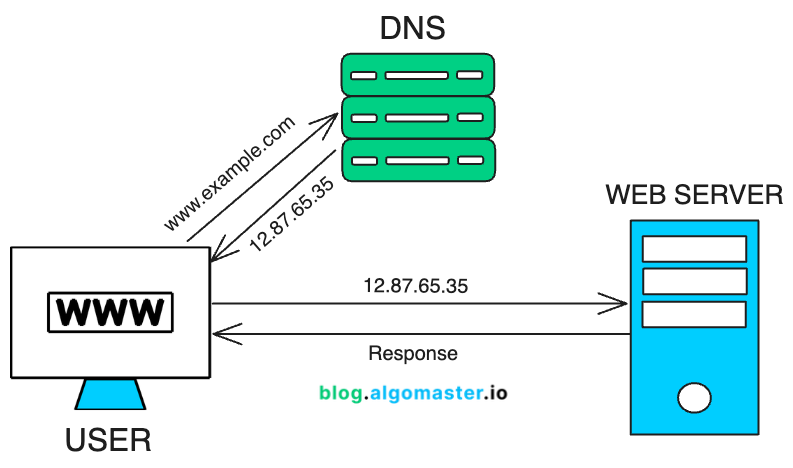
DNS 就像是互联网的电话簿。
它将人类可读的域名(例如,
example.com
)翻译成计算机用来识别网络上彼此的IP地址。
DNS 允许用户访问网站和服务,而无需记住数字IP地址。
例子: Route 53, Google Cloud DNS
4. 数据库
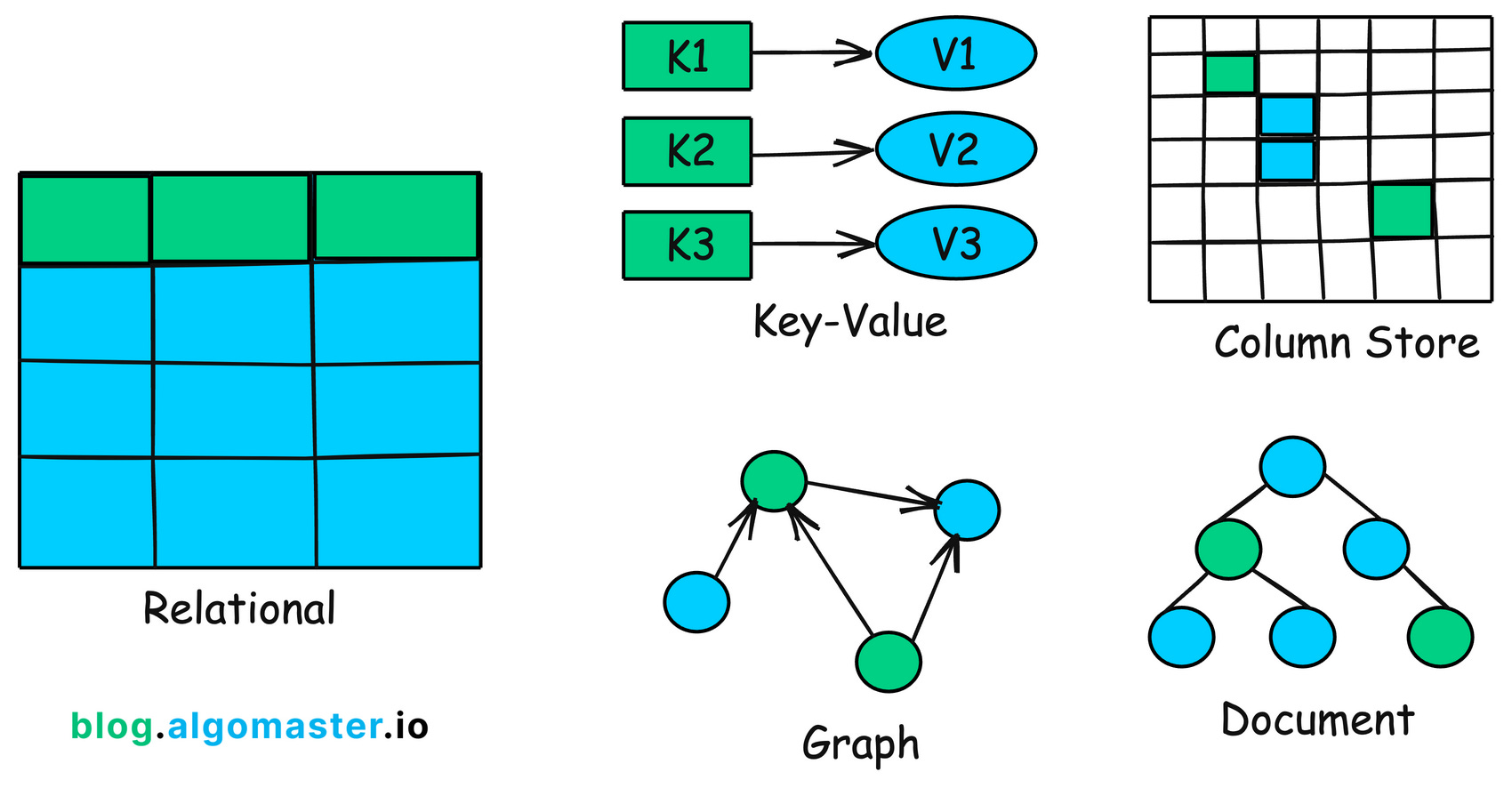
数据库 是核心存储单元。它们存储 结构化 或 非结构化 数据,应用程序依赖这些数据进行查询、更新和删除等操作。
关系型数据库(SQL)如 MySQL 或 PostgreSQL 提供具有 ACID 特性的结构化数据存储,而 NoSQL 数据库如 MongoDB 则更高效地处理非结构化的大量数据。
例子: Netflix 使用 Apache Cassandra(一种 NoSQL 数据库)来存储和检索大量的用户数据和流媒体日志。
5. Blob 存储
Blob(Binary Large Object) 存储是一种专为存储大量非结构化数据(如图像、视频和备份)而设计的存储服务,这些数据通常难以在常规数据库中管理。
Blob 存储非常适合处理大量媒体文件的应用程序,例如视频流服务(如 YouTube)、图像托管平台(如 Instagram)或提供多媒体内容的内容分发网络(CDN)。
例子: Amazon S3, Google Cloud Storage
6. 分布式缓存
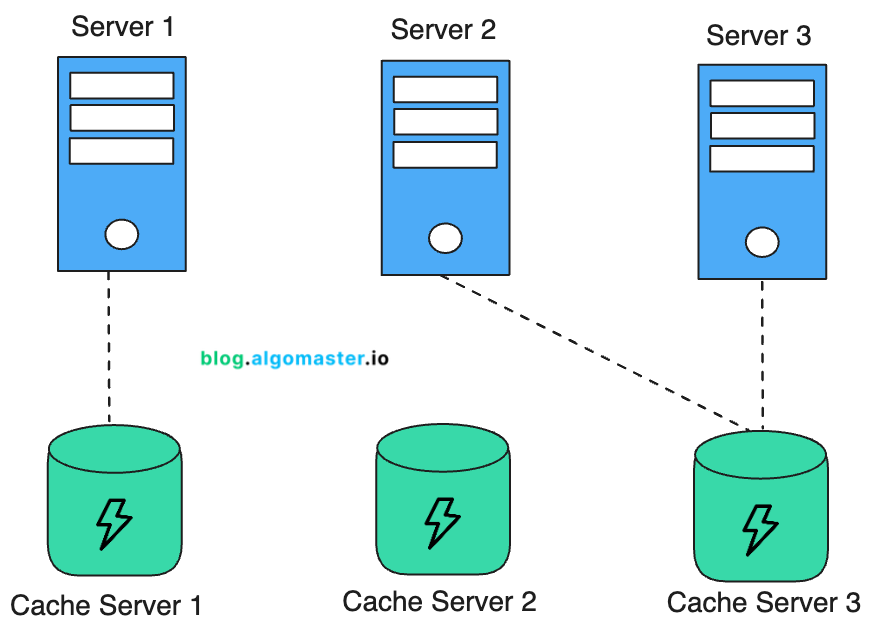
分布式缓存 在多个节点上存储经常访问的数据,使其更快地被检索,并减少主数据库的负载。
它对于扩展读取密集型应用程序非常有用,或者当某些数据片段被用户频繁访问时,例如用户会话或产品目录。
例子: Redis, Memcached
订阅以每周接收新文章。
7. 内容分发网络 (CDN)
CDN 是一个地理上分布的服务器网络,根据用户的位置提供静态和动态内容(如 HTML 页面、JavaScript 文件、图像)。
通过在靠近用户的边缘服务器上缓存静态内容,CDN 减少了延迟并加快了内容传输速度。
Netflix 使用 CDN 从靠近用户的边缘服务器提供视频内容,减少缓冲并提高流媒体质量。
例子: Cloudflare, Akamai
8. 速率限制器
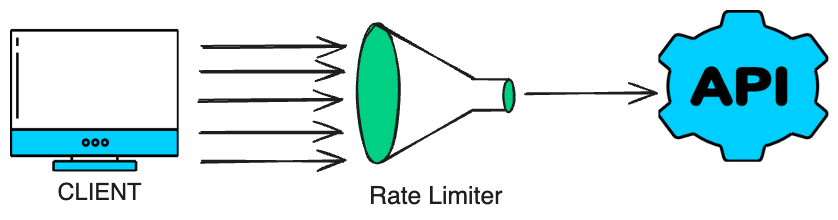
速率限制器 控制用户或系统在特定时间内对服务的请求数量。
它用于保护系统免受恶意攻击(例如,DDoS)或意外流量激增的影响。
流行的服务对其 API 应用速率限制,以控制用户/开发者在一定时间内可以发出的请求数量。
9. 分布式消息队列
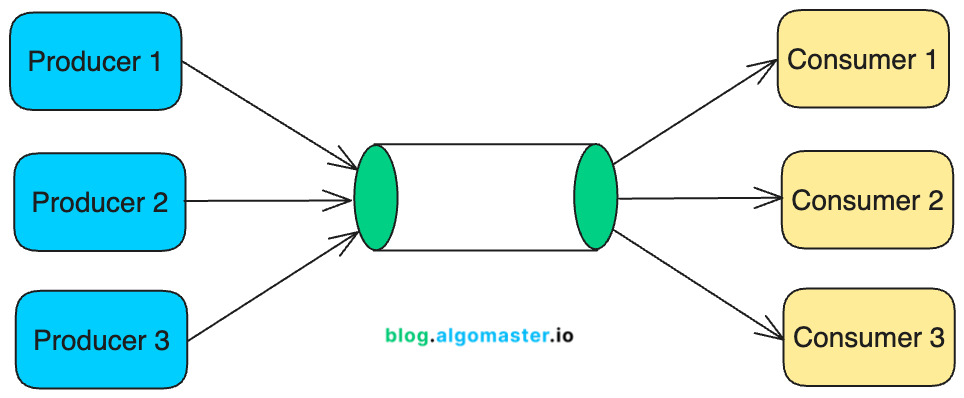
分布式消息队列 允许系统不同部分之间通过发送消息进行异步通信。
它们帮助解耦服务,确保即使消费者不可用,生产者也可以继续发送消息。
例子: Uber 使用 Apache Kafka 实时管理数百万次乘车事件,确保它们被可靠地处理并具备可扩展性。
10. 微服务
微服务 是一种架构风格,将应用程序分解为小的、松散耦合的服务,这些服务通过网络进行通信,通常使用 HTTP 或消息队列。
它使得应用程序的不同部分可以独立开发、部署和扩展。
例子: Amazon 使用微服务架构来管理其平台的不同部分,如支付、产品搜索和库存管理。
11. 分布式唯一 ID 生成器
分布式唯一 ID 生成器 是一种服务,在分布式系统中创建全局唯一标识符,而无需集中协调。
这些唯一 ID 对于跨多个服务器或区域操作的系统至关重要,以避免冲突并确保每个实体(如用户、交易或订单)都有一个独特的标识符。
在传统系统中,集中式数据库可能会生成自动递增的 ID,但在分布式系统中,这种方法不易扩展,并可能引入瓶颈。
分布式 ID 生成器通过允许多个系统独立生成 ID 而不发生冲突来解决这个问题。
例子: Twitter 的 Snowflake 在全球分布式系统中为每条推文生成唯一 ID。
12. 分布式任务调度器
分布式任务调度器 协调和管理跨多个节点的任务执行。它确保即使在分布式环境中,计划任务也能按时执行。
它帮助将系统的工作负载分解为单个任务,并将它们分配到不同的节点。调度器通过跟踪任务执行、监控故障并在必要时重试任务,确保每个任务都能完成。
它通常用于调度和执行周期性批处理任务,如数据备份、ETL、报告生成等。
例子: Apache Airflow、Celery、AWS Step Function
13. 发布-订阅系统
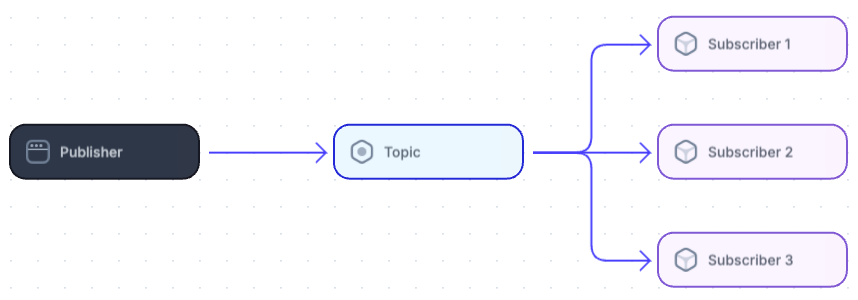
发布-订阅(pub-sub) 系统允许 一对多 的通信,发布者可以向多个订阅者发送消息,而无需知道他们是谁。
这种系统广泛用于解耦事件生产者和消费者。
每当有新消息发布时,所有订阅者会同时收到消息,实现实时通信。
示例: Amazon SNS, Google Cloud Pub/Sub
14. 分布式日志系统
分布式日志系统 将来自多个服务和服务器的日志聚合到一个中心位置,便于监控、分析和排查分布式系统的问题。
Uber 运营着一个复杂的微服务架构,产生大量日志。他们使用 ELK Stack (Elasticsearch, Logstash 和 Kibana)来收集、存储和分析全球服务的日志。
示例: Elastic Stack (ELK), Splunk
15. 监控系统
监控系统用于跟踪应用程序的健康状况、性能和正常运行时间。
它们收集 CPU 使用率、内存消耗、磁盘 I/O 和响应时间等指标,以确保系统高效运行。
在生产环境中应始终使用监控系统,以确保系统高效运行并及时解决问题。
示例: Prometheus, Grafana
希望你喜欢阅读这篇文章。
如果你觉得有价值,请点赞 ❤️ 并考虑订阅以获取每周更多内容。
如果你有任何问题或建议,请留言。
这篇文章是公开的,欢迎分享。
免费订阅以每周接收新文章。
查看我的 YouTube 频道 以获取更深入的内容。
在 LinkedIn 、 X 和 Medium 上关注我以保持更新。
查看我的 GitHub 仓库 以获取免费的面试准备资源。
希望你有美好的一天!
再见,
Ashish
文章来源:15 System Design Building Blocks You Should Know
关键问题与行动计划
关键问题 1: 如何评估分布式系统设计中的关键组件的市场需求和技术趋势?
行动计划:
- 行业分析:研究团队将针对当前市场上主要的分布式系统组件(如负载均衡器、反向代理、数据库等)进行深入分析,识别出各组件的市场需求、技术趋势及其在不同应用场景中的适用性。
- 竞争对手调研:数据团队将收集和分析主要竞争对手在分布式系统设计领域的产品和服务,评估其市场表现和用户反馈,以识别潜在的投资机会。
关键问题 2: 如何识别和评估新兴技术在分布式系统中的应用潜力?
行动计划:
- 技术前沿研究:研究团队将关注新兴技术(如边缘计算、无服务器架构、微服务等)在分布式系统中的应用案例,撰写技术白皮书,分析其对现有系统架构的影响及潜在的市场机会。
- 专家访谈:数据团队将联系行业专家和技术领袖,进行访谈以获取对新兴技术在分布式系统中应用的见解,形成对市场趋势的深度理解。
关键问题 3: 如何评估分布式系统设计的安全性和可靠性对投资决策的影响?
行动计划:
- 安全性评估框架:研究团队将制定一个评估框架,专注于分布式系统设计中的安全性和可靠性因素,分析这些因素如何影响投资决策和市场接受度。
- 案例研究:数据团队将收集和分析过去因安全性或可靠性问题导致的失败案例,评估其对投资回报的影响,以帮助投资决策时更好地理解风险。
请告诉我们你对此篇总结的改进建议,如存在内容不相关、低质、重复或评分不准确,我们会对其进行分析修正